
A prototyping web framework designed to help you deploy your interactive musical system or agent on the web without the need of having to learn web programming.
We present a system that converts a user's hand-drawn curves to a melody, for filling in missing measures in a monophonic music piece.
A deep reinforcement learning method that tranfers counterpoint patterns from J.S. Bach Chorales to compose countermelodies for Chinese folk melodies.
A deep learning system that allows a human musician to improvise a duet counterpoint with a machine partner in real time. We hope that this system will help revitalize the improvisation culture in classical music education and performance!
We propose a reinforcement learning framework for online music accompaniment in the style of Western counterpoint. The reward model is trained from J.S. Bach chorales to model intra- and inter-part interaction.
We present a neural language (music) model that tries to model symbolic multi-part music. Our model is part-invariant, i.e., it can process/generate any part (voice) of a music score consisting of an arbitrary number of parts, using a single trained model. After training, the generation is performed by Gibbs Sampling.
Separating a song into vocal and accompaniment components is an active research topic, and recent years witnessed an improved performance from supervised training using deep learning techniques. We propose to apply the visual information corresponding to the singers’ vocal activities to further improve the quality of the separated vocal signals.
We propose to leverage visual information captured from music performance videos to advance several music information retrieval (MIR) tasks, such as source association, multi-pitch analysis, and vibrato analysis. We also created two audio-visual music performance datasets, covering different musical instruments and voice.
We train a model to take the input of MIDI data, and output the visual performance as expressive body movements for pianist. It can be used for demonstration purpose for music learners, or immersive music enjoyment system, or human-computer interactions in automatic accompaniment systems. We show all the demo videos of the generated visual performance (as skeleton key points) compared with real human on same pieces.
A series of approaches to real-time beat, downbeat, and meter tracking for general music audio and singing voices.
A methodology for regularizing guitar tablature transcription systems using an inhibition loss with weights derived from co-occurence likelihoods estimated using a collection of symbolic tablature.
A methodology for learning a bank of sparse analytic filters to use as a frontend for music transcription models.
A complete piano music transcription system from transcribing notes from audio waveform to arranging as readable score notations
We address the "sustained effect" in piano music performance, caused by the usage of sustained pedal or legato articulations. Due to this effect, the mixture of energy between the sustained and following notes (non-notated in the score) always results in delay erros in score following systems. We propose to modify the audio feature representations to reduce the sustained effect and enhance the robustness of score following systems.
Live musical performances (e.g., choruses, concerts, and operas) often require the display of lyrics for the convenience of the audience. We propose a computational system to automate this real-time lyrics display process using signal processing techniques
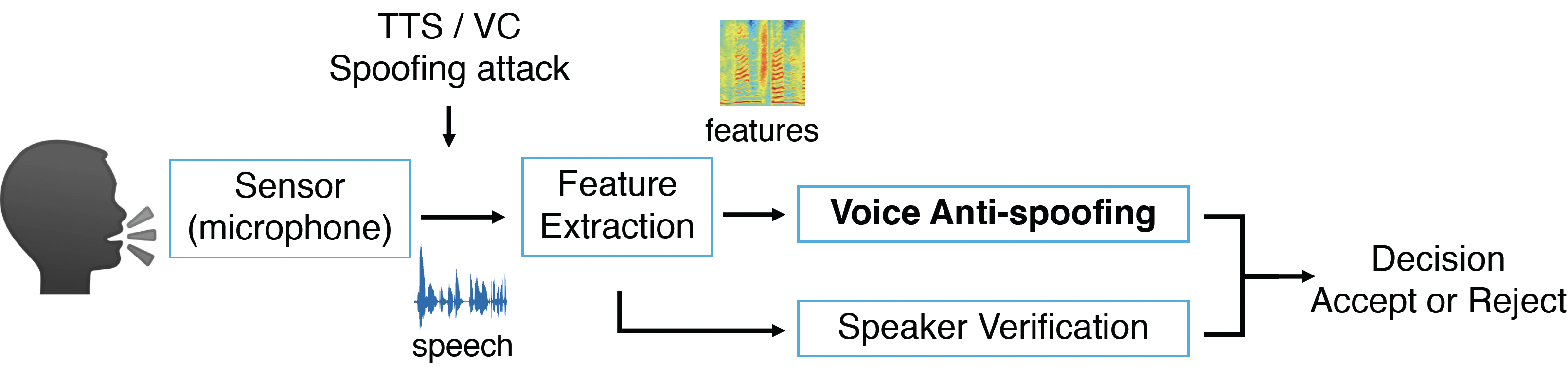
We study the anti-spoofing system to improve the reliability of speaker verification systems against synthetic and converted voice. We propose methods to generalize anti-spoofing to unseen synthetic attacks and channel variation.
We propose an end-to-end talking face generation system that can take a speech utterance, a face image, and an emotion condition (e.g., happy, angry, etc.) as input, to render a talking face expressing that emotion.
We propose a system that can generate talking faces from input noisy speech and a reference image.
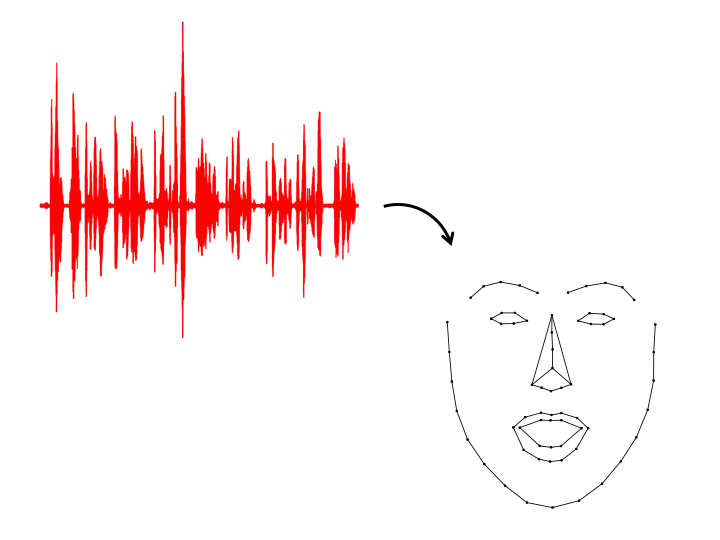
We propose to use an LSTM network to generate 2D landmarks of a talking face from acoustic speech and a 1D convolutional network to generate 3D landmarks from noisy speech waveforms.
We propose an adversarial training method for speech super-resolution or speech bandwidth extension.
we propose an audio-visual Audio-Visual Deep Clustering model (AVDC) to integrate visual information into the process of learning better feature representations (embeddings) for Time-Frequency (T-F) bin clustering.
We propose to make general audio databases content-searchable using vocal imitation of the desired sound as the query key: A user vocalizes the audio concept in mind and the system retrieves audio recordings that are similar, in some way, to the vocalization.
