Speaker Verification Anti-Spoofing / Audio Deepfake Detection
|
This project is supported by the National Science Foundation under grant No. 1741472, titled "BIGDATA: F: Audio-Visual Scene Understanding". |
What is the problem?
Automatic speaker verification systems are vulnerable to spoofing attacks, including text-to-speech, voice conversion, replay, etc. Speech anti-spoofing system is designed to discern spoofing attacks from human natural speech.
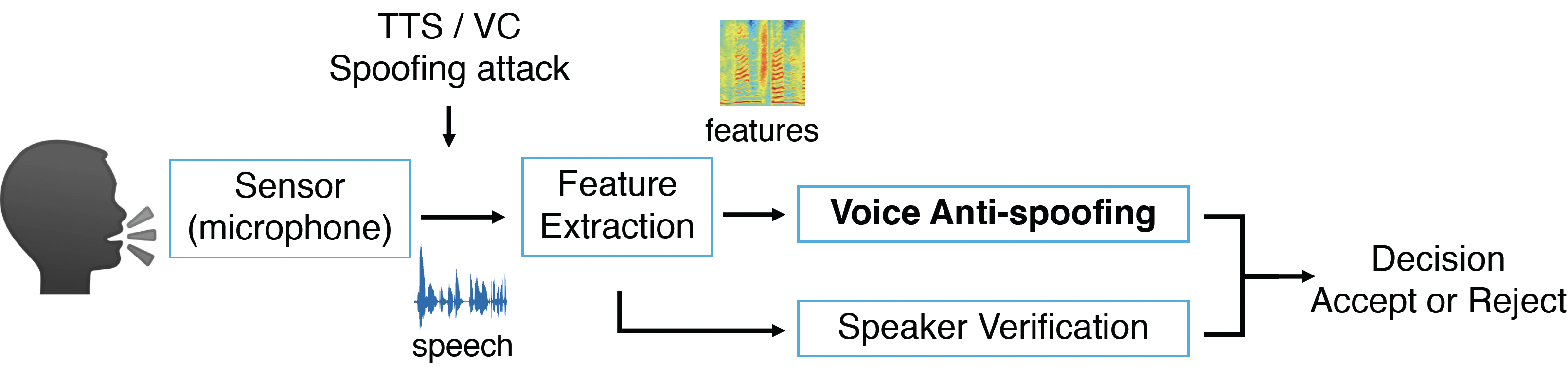
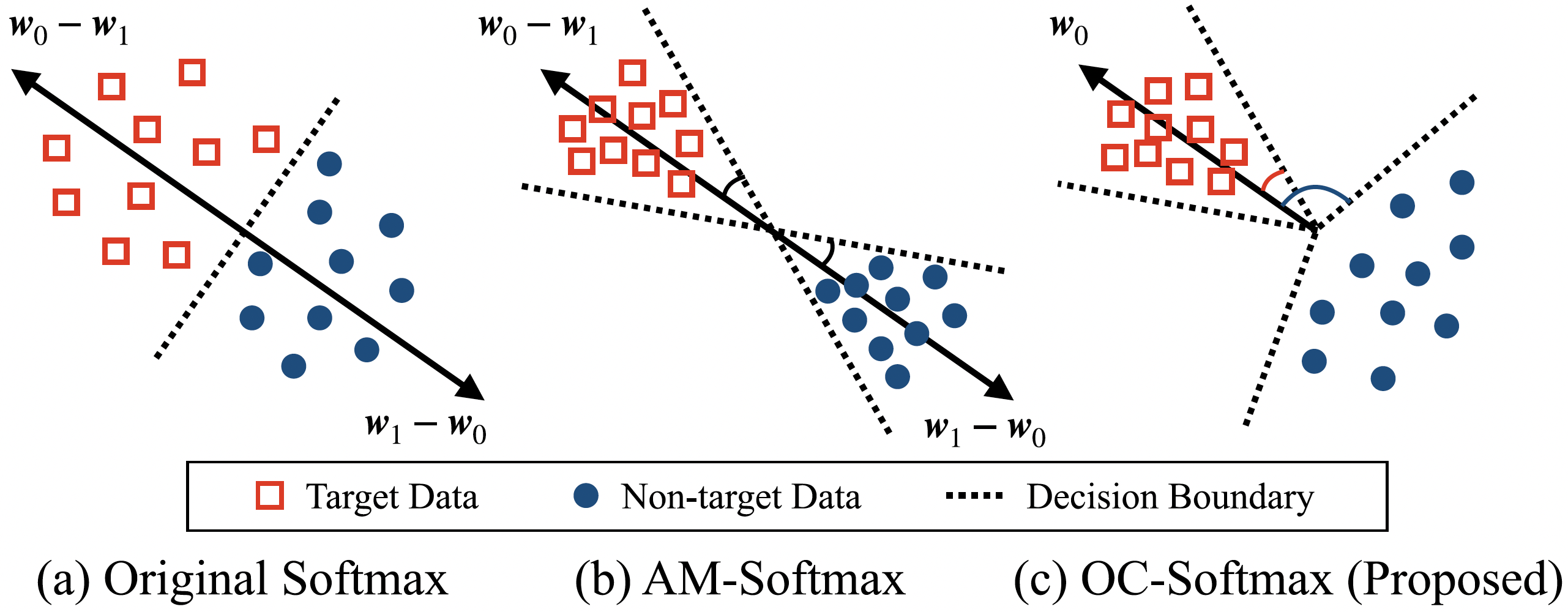
Generalize to unseen synthetic spoofing attacks
One main issue of speech anti-spoofing research is the generalization to unseen attacks, i.e., synthesis methods not seen in training the anti-spoofing models. We propose one-class learning method [1] where we compacted the natural speech representations and separated them from the fake speech with a certain margin in the embedding space. Our system achieved state-of-the-art performance in terms of detecting unseen attacks.
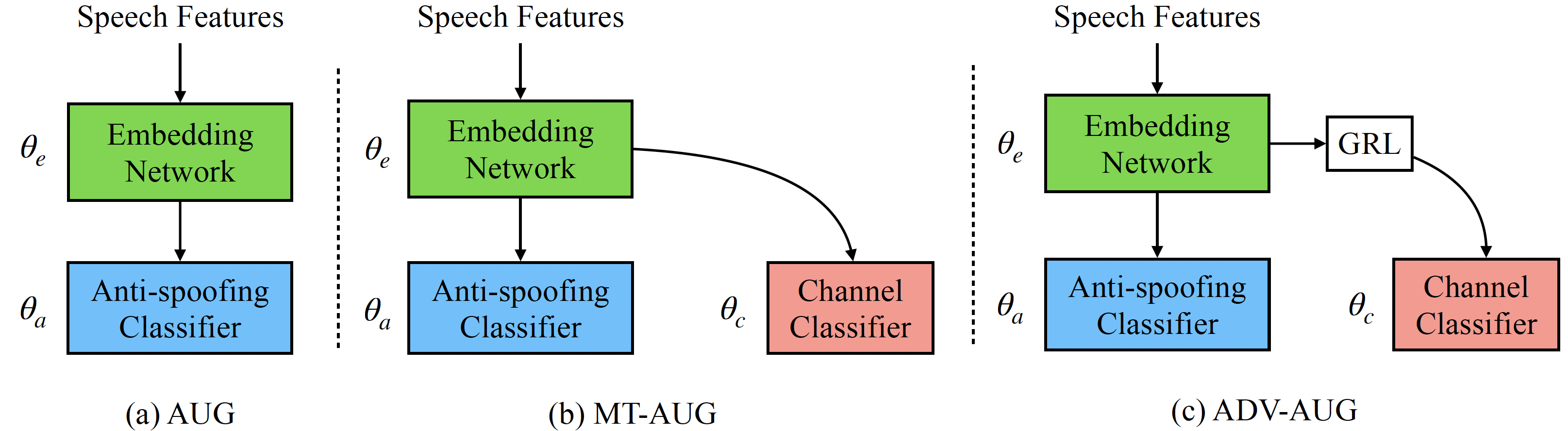
Generalize to channel variation
Another issue in speech anti-spoofing is the robustness to acoustic and telecommunication channel variations. In our Interspeech work [2], we showed that existing systems suffer from performance degradation when there is a channel mismatch between training and testing. We then proposed several channel-robust training strategies to improve the generalization ability to channel variations.
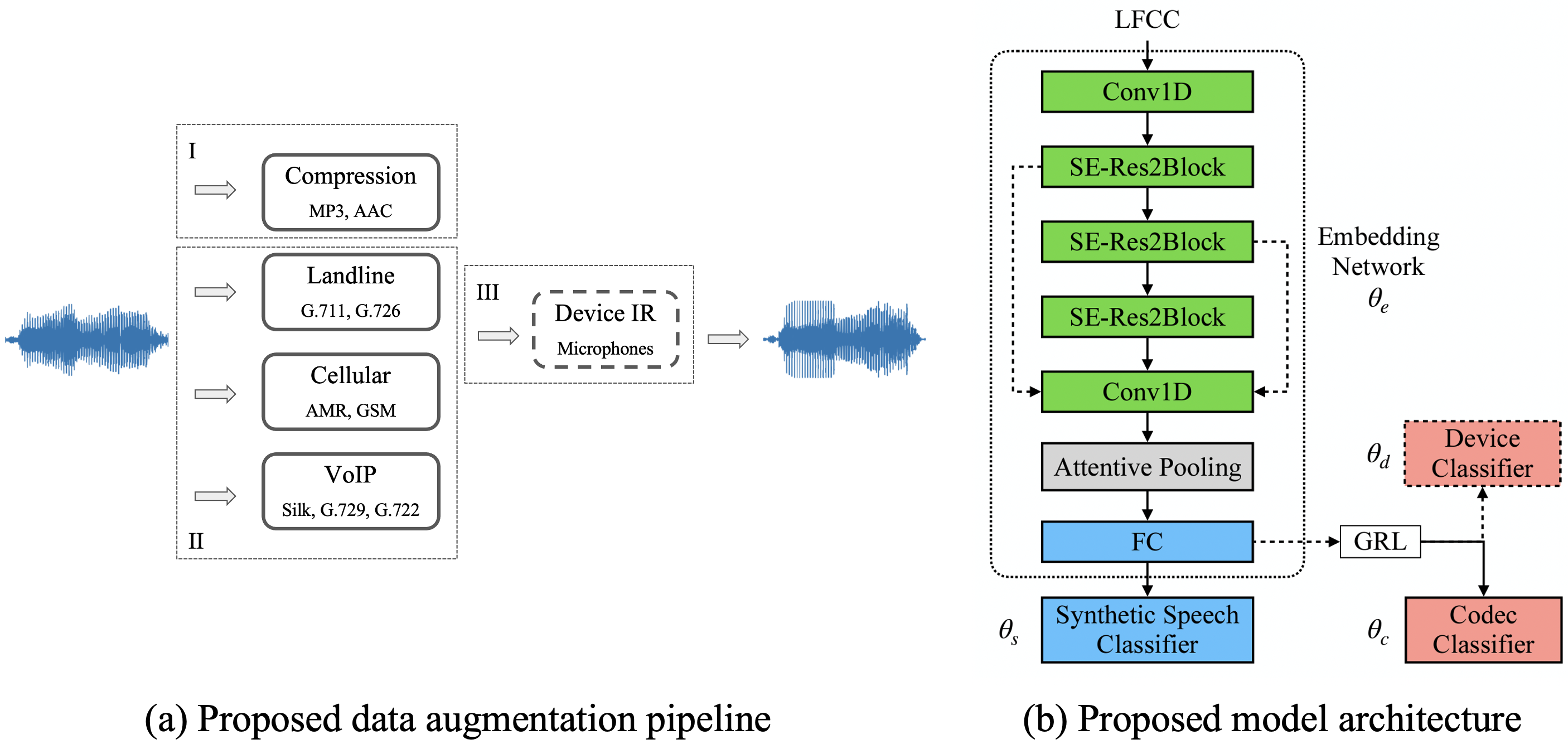
ASVspoof 2021 Challenge
Different from previous ASVspoof challenges, the LA task this year presents codec and transmission channel variability, while the new task DF presents general audio compression. Built upon our previous research work on improving the robustness of the SSD systems to channel effects, we propose a channel-robust synthetic speech detection system for the challenge. We adopted ECAPA-TDNN as our backbone, incorporated one-class learning with channel-robust training strategies, and achieved top performance [3].
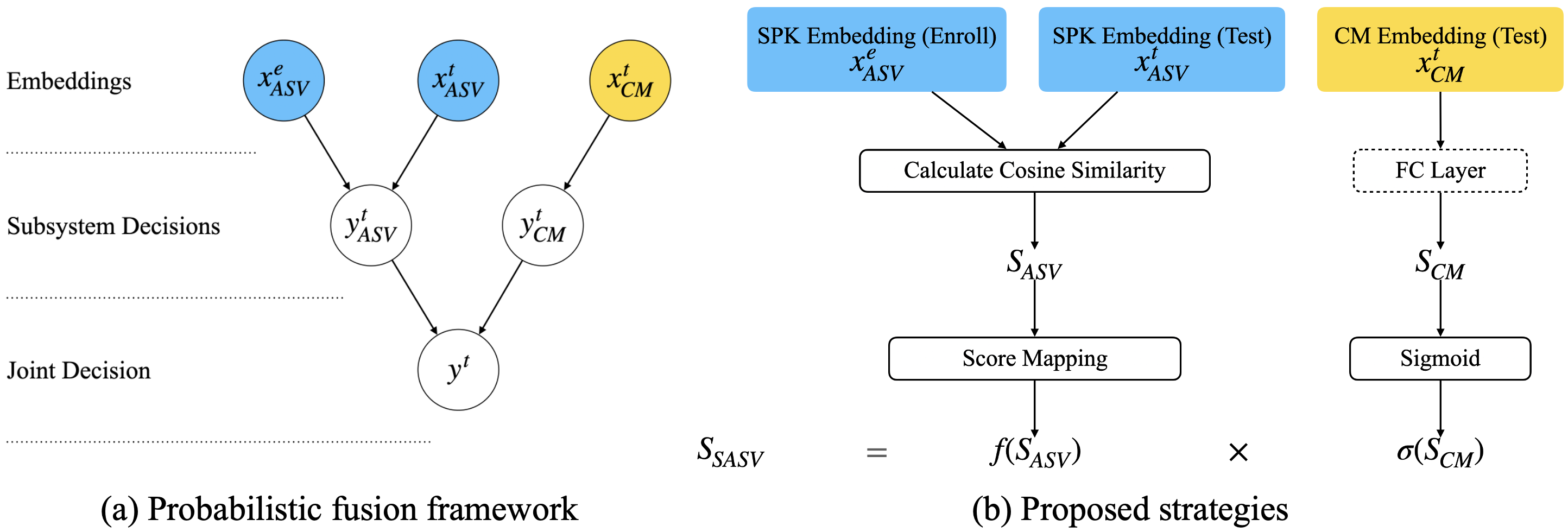
Joint optimization with speaker verification (SASV Challenge 2022)
Another issue is the joint optimization of speaker verification and anti-spoofing to strengthen identity authentication. Our work [4] proposed a probabilistic framework to optimize speaker-aware anti-spoofing conditioned on speaker verification's confidence scores.
Publications
[1] You Zhang, Fei Jiang, and Zhiyao Duan, One-class learning towards synthetic voice spoofing detection, IEEE Signal Processing Letters, vol. 28, pp. 937-941, 2021. <link> <pdf> <code> <poster> <slides> <video>
[2] You Zhang, Ge Zhu, Fei Jiang, and Zhiyao Duan, An Empirical Study on Channel Effects for Synthetic Voice Spoofing Countermeasure Systems, in Proc. Interspeech 2021, pp. 4309-4313, 2021. <pdf> <link> <code> <video> <slides>
[3] Xinhui Chen*, You Zhang*, Ge Zhu*, and Zhiyao Duan, UR channel-robust synthetic speech detection system for ASVspoof 2021, in Proc. 2021 Edition of the Automatic Speaker Verification and Spoofing Countermeasures Challenge Workshop (ASVspoof), 2021, pp. 75-82. (* equal contribution) <pdf> <link> <code> <video>
[4] You Zhang, Ge Zhu, and Zhiyao Duan, A probabilistic fusion framework for spoofing aware speaker verification, in Proc. The Speaker and Language Recognition Workshop (Odyssey), 2022, pp. 77-84. <pdf> <link> <code> <video> <slides>