Audio-Visual Speech Source Separation
|
This project is partially supported by the US National Science Foundation under grant No. 1741472, titled "BIGDATA: F: Audio-Visual Scene Understanding", the National Natural Science Foundation of China under Grant No. 61473167, 61751308 and 61876095, and the German Research Foundation (DFG) in Project Crossmodal Learning DFG TRR-169. |
What is the problem?
Speech separation aims to separate individual voices from an audio mixture of multiple simultaneous talkers. Audio-only approaches show unsatisfactory performance when the speakers are of the same gender or share similar voice characteristics. This is due to challenges on learning appropriate feature representations for separating voices in single frames and streaming voices across time. Visual signals of speech (e.g., lip movements), if available, can be leveraged to learn better feature representations for separation.
In this project, we propose two novel models to solve the source permutation problem in the state-of-the-art speaker-independent speech separation methods. The first proposed model is an Audio-Visual Matching network (AV-Match) which learns the correspondence between voice fluctuations and lip movements. The proposed matching-based audio-visual network can be combined with any audio-only speech separation methods to improve the separation quality. However, the separation ability of the matching-based model is limited by the performance of the audio-only methods. We thus further develop an end-to-end Audio-Visual Deep Clustering model (AVDC) to integrate visual information into the process of learning better feature representations (embeddings) for Time-Frequency (T-F) bin clustering. This fusion-based model breaks the limitations of the matching-based one and improves the separation quality by a large margin.
The Audio-Visual Matching Approach
The proposed audio-visual matching model integrates both motion (optical flow) and appearance (gray image) information of the lip region to correct spectrogram masks predicted by the audio-only separation model [1] for better separation. As shown in the figure below, the permutation problem primarily exists in the beginning quarter time frames of the masks predicted by the audio-only model, and the proposed audio-visual matching network can correct this problem by assigning the predicted masks to the correct speakers.
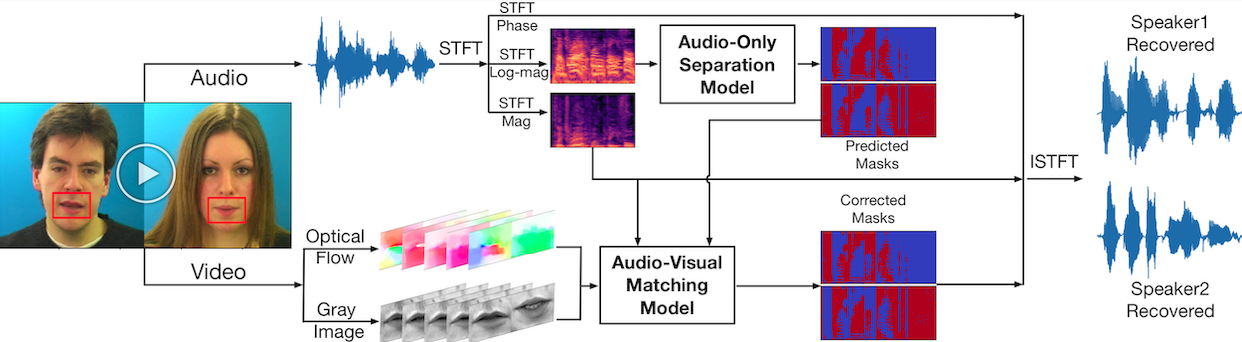
Audio and visual streams are encoded as frame-wise embeddings, we compute inner products of temporally aligned audio and visual embeddings as similarity measure. Every five audio frames correspond to one video frame. With these similarities, we can assign the separated sources to correct speakers, thus relieving the permutation problem.
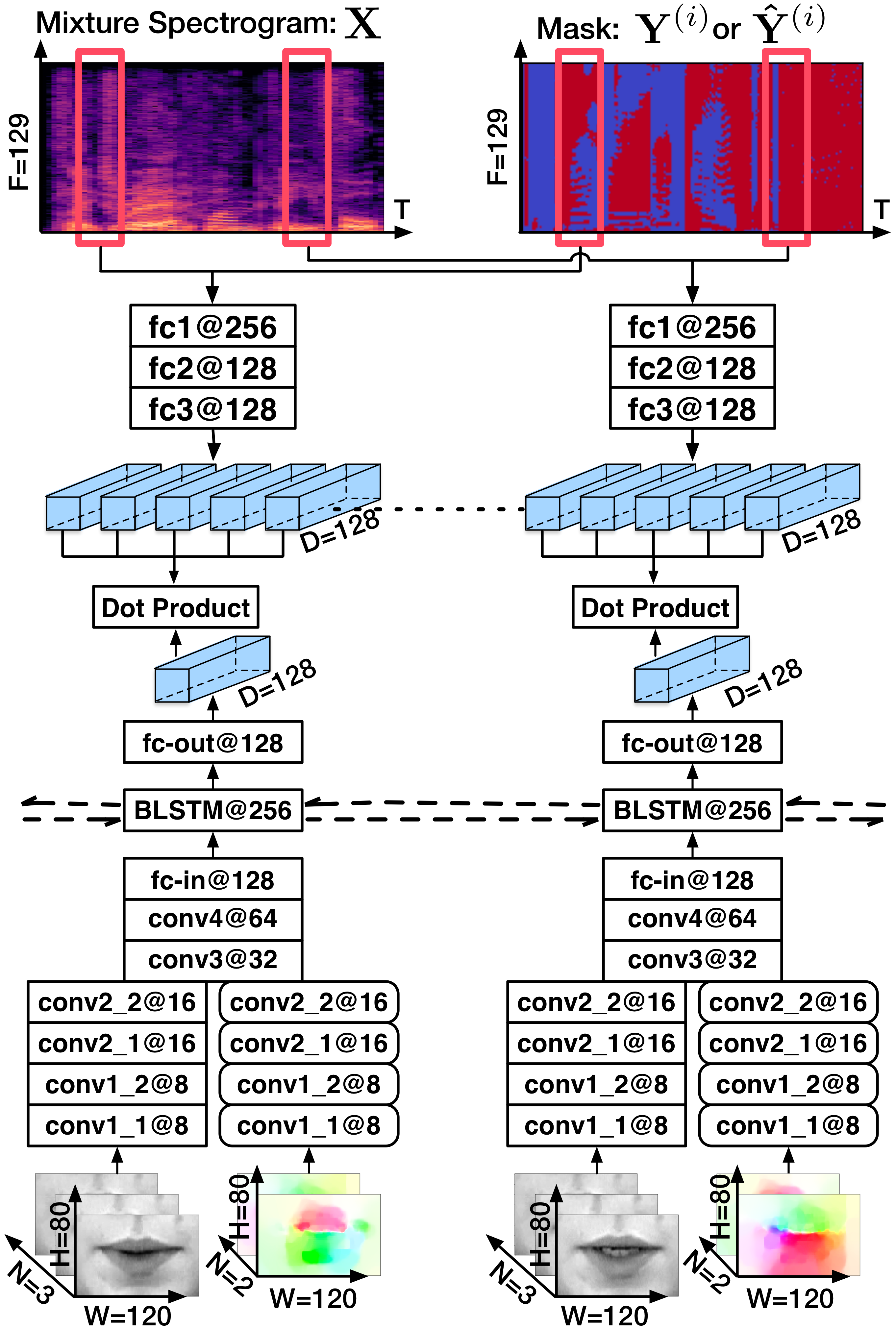
The matching-based method has following drawbacks:
- First, since the AV-Match model is not end-to-end, its separation ability is limited by the audio-only models.
- Second, the possible number of permutations increases exponentially with the number of speakers, resulting in significant accuracy drop of the AV-Match model. The AV-Match model thus can not be easily generalized over speech mixtures of different numbers of speakers
The Audio-Visual Fusion Approach
As shown in following figure, the Audio-Visual Deep Clustering (AVDC) model receives similar inputs as that of the matching-based model and directly predicts T-F masks for the speakers. The predicted masks are used to reconstruct source signals using the speech mixture’s magnitude and phase spectrograms. Contributions of the AVDC model come in threefold:
- First, the proposed AVDC model employs a novel two-stage audio-visual fusion strategy for speech separation, outperforming single-stage fusion in the experiments.
- Second, the AVDC model learns audio-visual "speaker-wise T-F embeddings" which alleviate the source permutation problem that frequently happens for audio-only methods on same-gender speech mixtures.
- Third, the proposed model can generalize over speech mixtures of different numbers of speakers and shows a certain degree of robustness on partially observed videos.
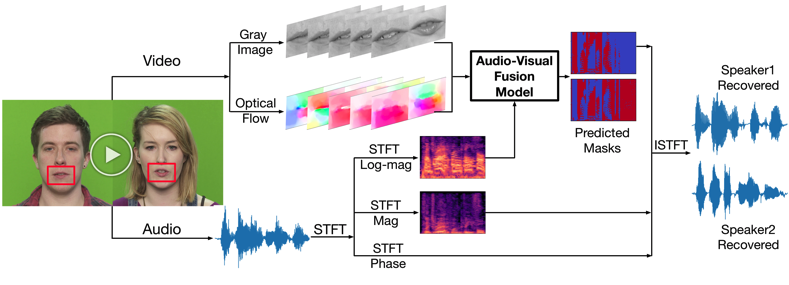
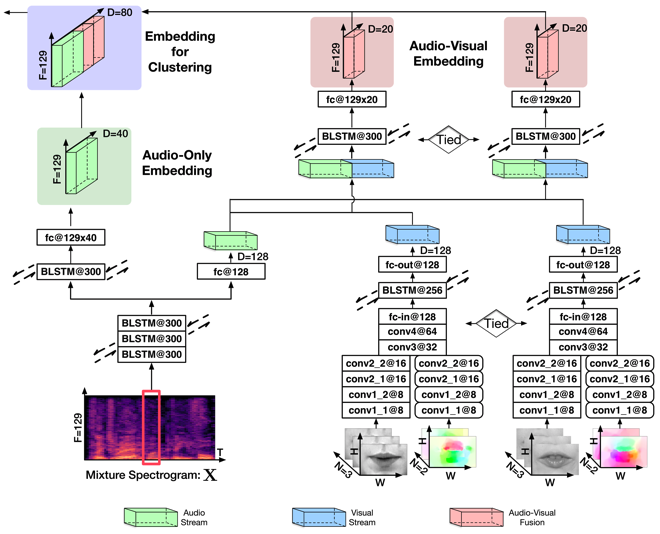
The core part of this approach is the Audio-Visual Deep Clustering (AVDC) model, which is illustrated below. It adopts a two-stage fusion strategy to integrate the audio and visual modalities. The first-stage fusion computes speaker-wise audio-visual T-F embeddings for each speaker in the mixture, while the second-stage fusion concatenates these audio-visual embeddings with the audio-only embedding computed using an audio-only Deep Clustering (DC) method for the final clustering of T-F bins.
Experiments on 2-speaker mixtures
Comparison of the separation results
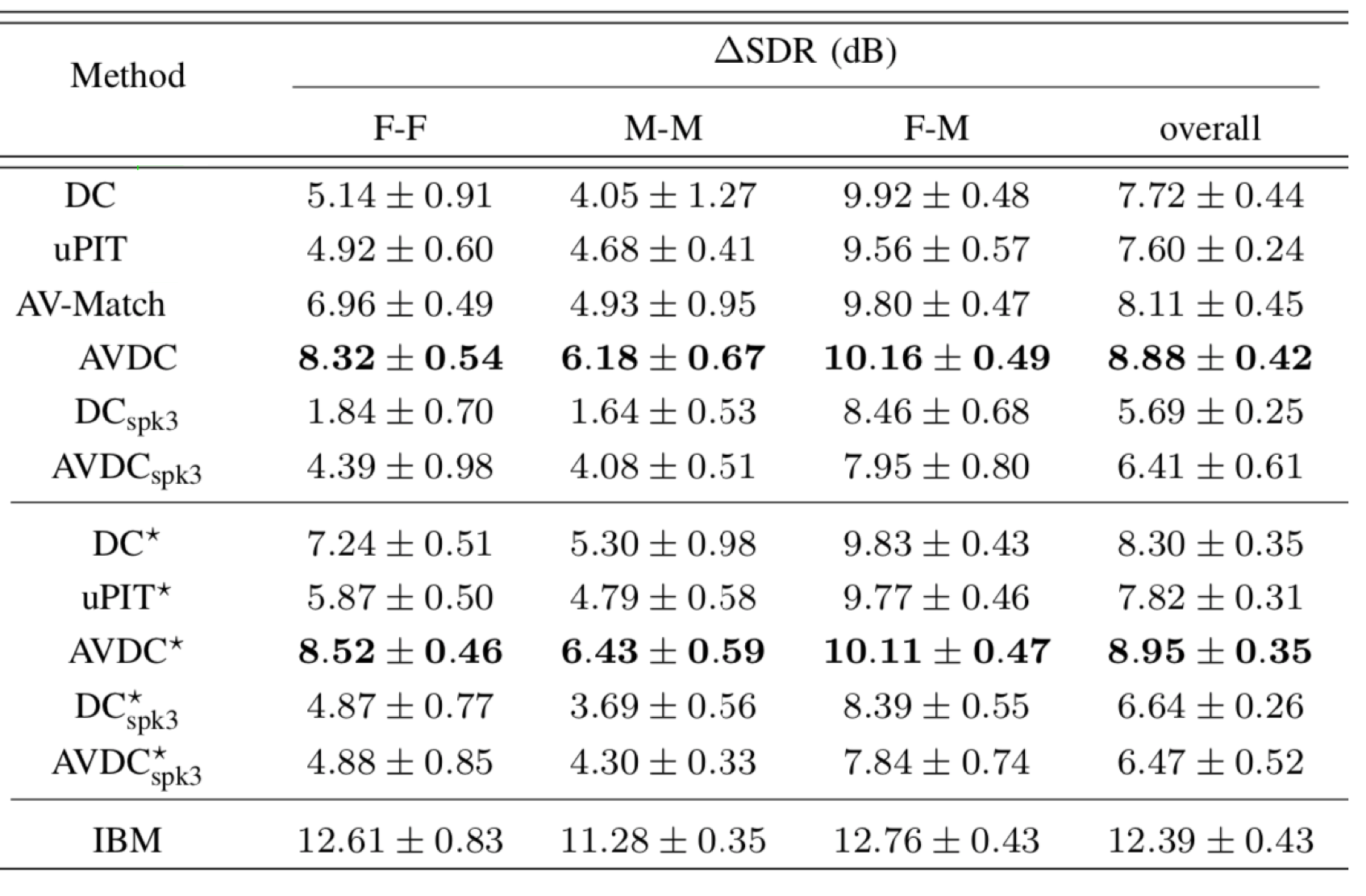
Based on the above table, we have following conclusions
- First, the proposed AV-Match model and the AVDC model outperform the audio-based DC method and the uPIT method on both the GRID and TCD-TIMIT datasets.
- Second, the AVDC approach significantly outperforms three other state-of-the-art audio-visual approaches. The AV-Match method is designed to fix source permutation problems in DC, hence its performance is bounded by DC⋆. The Look-to-Listen model [3] and Noise-Invariant model [4] report an average SDR of 4.1 dB and 0.4 dB on the TCD-TIMIT dataset respectively, while the proposed AVDC achieves 7.86 dB.
- Third, the AVDC method is able to generalize across mixtures with different number of speakers. Although the performance degrades during generalization, we can still see performance improvements introduced by visual information when camparing with the DC method. The uPIT [2] and AV-Match methods, however, cannot be easily generalized across different numbers of speakers.
Separation Demos
Original mixture and groud-truth:
Audio-based deep clustering method [1]:
AV-Match method:
AVDC method:
Experiments on 3-speaker mixtures
Comparison of the separation results
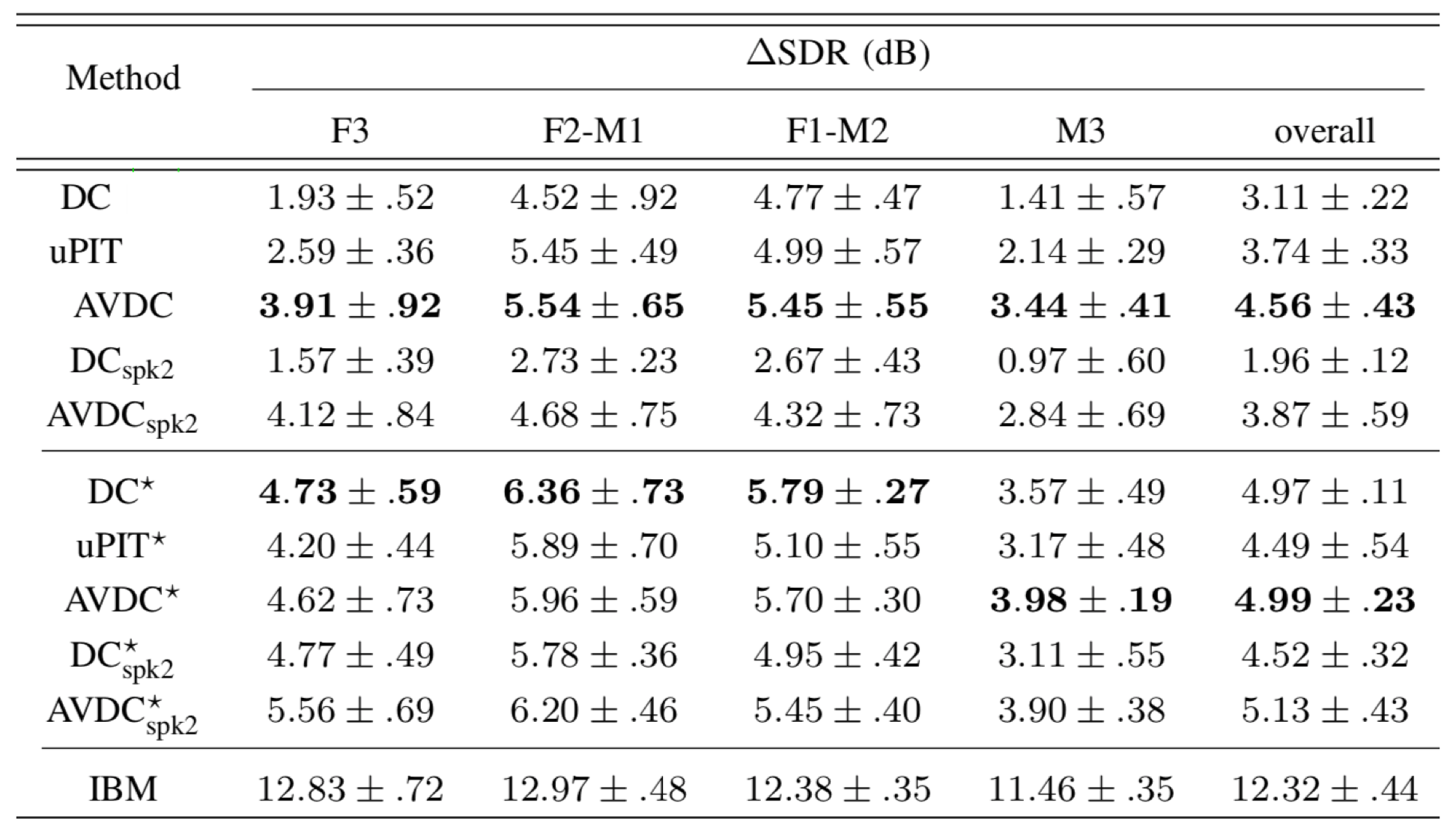
We have following conclusions based on the above table:
- First, we can see that 3-speaker separation is much more difficult than 2-speaker separation, as the performance of all methods in all conditions drop significantly. Nevertheless, the proposed AVDC approach outperforms DC and uPIT method.
- Second, the performance gap between AVDC-AVDC⋆ is much more smaller than those of DC-DC⋆ and uPIT-uPIT⋆, indicating that AVDC model has more advantages in alleviating permutation errors through audio-visual matching.
- Third, the performance of model trained on 2-speaker mixtures decreases slightly comparing to the one trained on 3-speaker mixtures, suggesting that in unmatched conditions, visual information shows great advantages for speech separation.
Separation Demos
Original mixture and groud-truth:
Audio-based deep clustering method [1]:
AVDC method:
Ablation Study
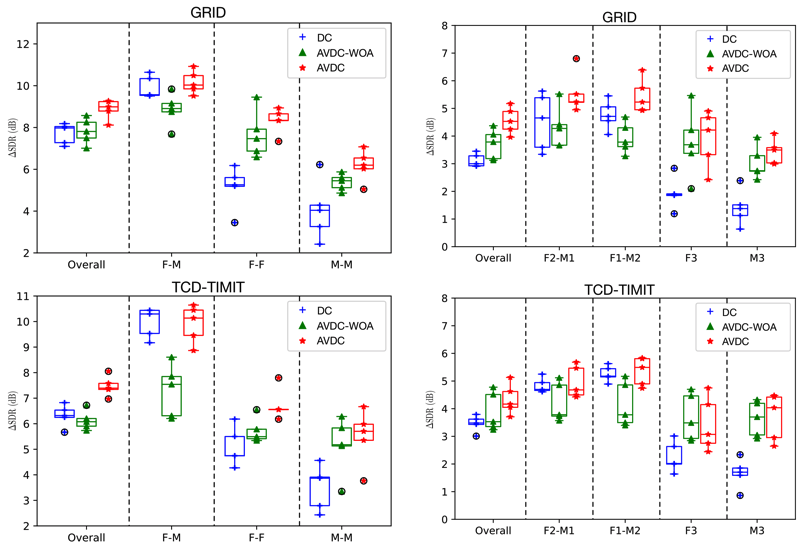
For the ablation study, we have following conclusions:
- First, across all kinds of mixtures and both datasets, the proposed AVDC model significantly outperforms the AVDC-WOA model. This suggests that the integration of audio embeddings in the second-stage audio-visual fusion of AVDC significantly improves the separation performance.
- Second, on same-gender mixtures, the AVDC-WOA model significantly outperforms DC, while on different-gender mixtures, it significantly underperforms DC. In fact, on different-gender mixtures, DC already achieves a similar performance as the proposed AVDC. This suggests that the audio-visual embedding learned in the first-stage fusion is only helpful for same-gender mixtures, where the source permutation problem is the major source of error. On different-gender mixtures, audio-visual matching is not that helpful for improving speech separation performance.
Audio-visual Embedding Visualization
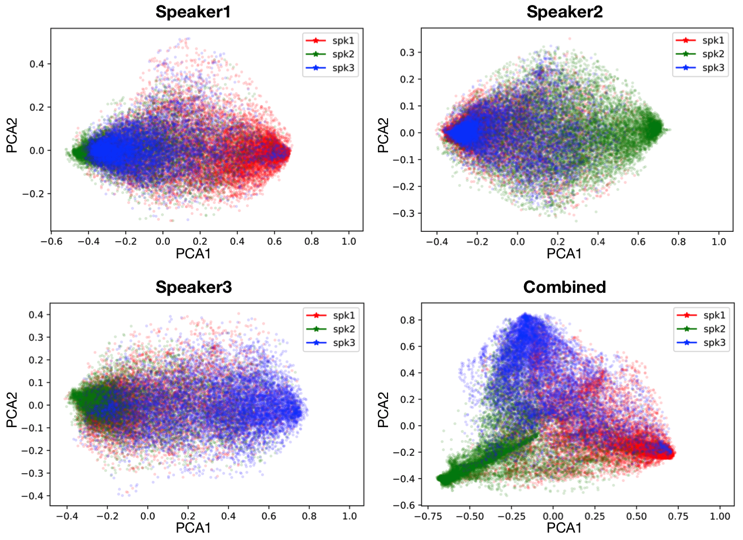
- Each of the first three subfigures clearly shows a 2-cluster clustering effect, where the target speaker is separated from the other two speakers that are essentially mixed up.
- The last subfigure performs PCA on the combined (concatenated) embedding vectors of all of the 3 speakers. It can be seen that all of the 3 speakers are well separated, providing further evidence that the AV embeddings help separate mixture audio into source components and consistently assign source components to correct sources.
Publications
Rui Lu, Zhiyao Duan, and Changshui Zhang, Listen and look: audio-visual matching assisted speech source separation, IEEE Signal Processing Letters, vol. 25, no. 9, pp. 1315-1319, 2018.
Rui Lu, Zhiyao Duan, and Changshui Zhang, Audio–Visual Deep Clustering for Speech Separation, IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 27, no. 11, pp. 1697-1712, 2019.
References
[1] J. R. Hershey, Z. Chen, J. Le Roux, and S. Watanabe, “Deep clustering: Discriminative embeddings for segmentation and separation,” in 41th International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2016.
[2] M. Kolbaek, D. Yu, Z.-H. Tan, and J. Jensen, “Multitalker speech separation with utterance-level permutation invariant training of deep recurrent neural networks,” IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 25, no. 10, pp. 1901–1913, 2017.
[3] A. Ephrat, I. Mosseri, O. Lang, T. Dekel, K. Wilson, A. Hassidim, W. T. Freeman, and M. Rubinstein, “Looking to listen at the cocktail party: A speaker-independent audio-visual model for speech separation,” in Proc. ACM SIGGRAPH, 2018.
[4] A. Gabbay, A. Shamir, and S. Peleg, “Visual speech enhancement,” in Proc. Interspeech, 2018, pp. 1170–1174.