Research Before AIR Lab
Research Objective
The objective of my research is to design computational systems that are capable of analyzing and processing auditory scenes. I call this Computer Audition. Although audition is natural for humans, computer audition remains challenging and once it succeeds, it will represent a fundamental advance in Audio Signal Processing and Intelligent Systems. It will also improve our ability to access and manipulate audio data, enabling new multimedia applications and interactions for experts and novices alike.
Auditory scenes are difficult to parse because source signals composing them overlap and interfere with each other at the same time and frequency. A successful computer audition system must be able to access source signals in spite of the other interfering sources. This challenge raises two fundamental questions:
1) How do we discover and separate a sound event from an audio mixture?
2) What sound events belong to one source versus other sources?
To answer these questions, I performed research at three levels:
1) Sound source tracking (e.g. identifying footsteps and streaming them together, estimating the pitch of a source and tracking it over time);
2) Audio source separation (e.g. extracting vocals from music, removing noise to enhance speech);
3) Leveraging external information (e.g. a musical score or speech transcript) to improve separation and manipulation of sound objects and sources.
Sound Source Tracking
Sound source tracking, i.e. identifying sound objects and streaming them into sources, is fundamental in analyzing an auditory scene. I have done significant work by focusing on Multi-pitch Estimation and Streaming (also called Tracking), i.e. estimating a pitch trajectory (stream) for each harmonic source (e.g. harmonic musical instruments, vocals and speech) in an audio mixture. Accurate, reliable multi-pitch estimation and streaming would be of great utility in many tasks, including music transcription, speech recognition, melody-based music search, etc.
I developed a two-stage method for multi-pitch estimation and streaming, illustrated in the following figure. It can deal with different types of harmonic sources, including polyphonic music and multi-talker speech.
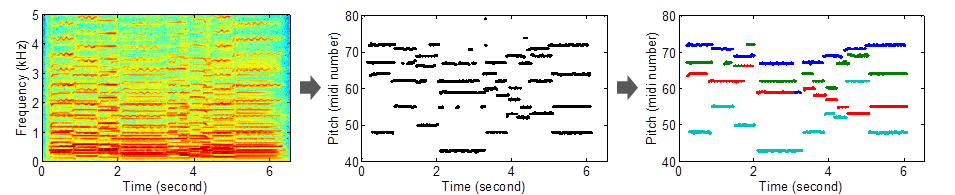
The first stage (from the left panel to the center panel) is multi-pitch estimation. In this stage, we estimate concurrent pitches (black dots in the center panel) of all sources in each time frame from the spectrogram (the left panel) of an audio mixture. The second stage (from the center panel to the right panel) is multi-pitch streaming. In this stage, we stream the pitch estimates in different frames according to sources, i.e. coloring the black dots in the center panel with different colors.
A more detailed description and sound examples can be found here. Code can be downloaded here: the complete system <mpe_mps.zip>, the MPE component <mpe.zip>, and the MPS component <mps.zip>.
Audio Source Separation
One step forward from source tracking is source separation, i.e. recovering source signals from the mixture. It is of great utility for many further processing tasks, including talker identification, speech recognition, post production of existing recordings, and structured audio coding. I focus on separating multiple sources from a single-channel mixture.
Unsupervised Music Source Separation
When prior analysis of the individual sound sources composing the mixture is not possible, the problem is considered blind, or unsupervised. I developed an unsupervised method to separate musical instruments and vocals in music, based on harmonic structure (relative amplitudes of harmonics) analysis. I found that harmonic structure is approximately invariant for sounds of each instrument within a narrow pitch range, but is significantly different for different instruments. All possible harmonic structures in the mixture were extracted and then clustered into several clusters, each of which corresponds to an instrument. An average harmonic structure model was calculated for each cluster and was used to separate its signal. Some sound examples can be found here.
Semi-supervised Speech Enhancement
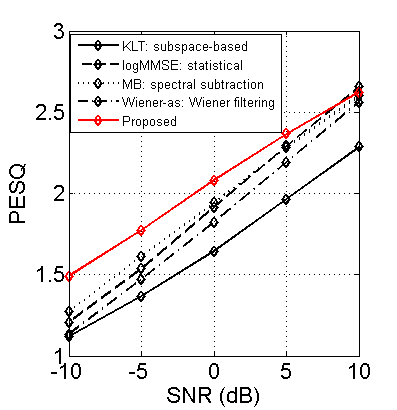
In some scenarios, when prior analysis is available for some sources (e.g. background noise in teleconferencing) but not for the others (e.g. speech of attendee), the problem is considered semi-supervised. Semi-supervised separation based on probabilistic latent component analysis (PLCA) has shown success in many scenarios, especially for non-stationary inharmonic sources. However, existing algorithms only work offline. They cannot be applied in online/real-time applications such as speech enhancement (separating speech from noise) in teleconferencing. I developed an online algorithm for PLCA-based semi-supervised separation. Experiments on speech enhancement show that it outperforms four categories of classical algorithms in non-stationary noise environments, see the figure on the right.
Sound examples can be found here.
Leveraging External Information for Audio Analyais and Manipulation
Humans often leverage external information to analyze auditory scenes. For example, reading a musical score helps musicians enjoy and study a symphony. Leveraging textual, visual and other kinds of information allows a computer audition system to accomplish tasks that could not be accomplished by processing audio alone. I focus on leveraging musical score information to improve music audio source separation and manipulation.
Soundprism
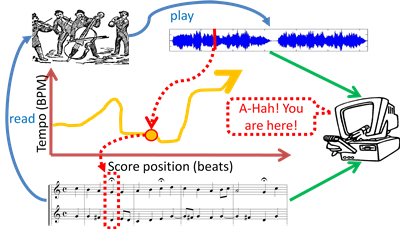
Soundprism is an online score-informed source separation system. Given a piece of polyphonic music and its MIDI score, Soundprism first aligns the score with the audio, then refines the multi-pitch estimates of the audio using the score notes information, and finally separates the audio sources. The whole process is performed in an online fashion. I envision that Soundprism can be implemented as a smart phone app, as shown in the figure on the right.
A detailed description of Soundprism can be found here. Sound examples can be found here. Code can be downloaded here.

Real-time Audio-score Alignment (Score Following)
Score following is the first step of Soundprism. It is not trivial since the temporal dynamics of audio performances (instantiation) are often significantly different from those of the score (abstraction). In addition, rich timbral patterns in polyphonic audio blur its mapping to the abstracted score. I developed a novel approach to align a multi-instrument polyphonic music audio with its score. It models an audio performance as a path in a two-dimensional performance space (state space). Finding the mapping is achieved by estimating the path (hidden states). A poster illustrating the approach can be found here. Sound examples can be found here.
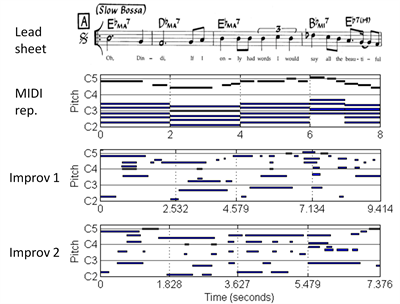
Aligning Jazz Improvisation with Lead Sheets
For semi-improvised music like Jazz, audio-score alignment is more challenging. The score, being more abstract, only specifies a basic melody, several chords and a musical form. The performer “composes” the details on the fly. The figure on the right shows several measures of a Jazz lead sheet, the MIDI representation of the lead sheet, and two improvised performances.
I developed an approach that aligns polyphonic Jazz audio with their lead sheets, without need for a separate microphone for each instrument. Improvisations in these performances include note/chord/rhythm changes, and unexpected structural changes such as jumps and repetitions. A poster illustrating the approach can be found here. Sound examples can be found here.