Piano Music Transcription into Music Notation
What is Automatic Music Transcription?
Music Transcription is the process of notating a music piece solely by listening. Imagine you are a pianist and you hear a nice piece that you would like to play, but the score is not available, which is typical for certain music genres like jazz improvisations. Then you have to patiently listen to the piece over and over, while writing down all the notes. Musicians spend a considerable amount of time training their ears and their transcription skills, but the transcription process is usually quite time consuming. Automatic Music Transcription (AMT) aims at automating this process by using computers and computer programs, so instead of transcribing the piece manually, you just feed the audio to a computer, and the computer generates the music score for you.
Why is it important?
AMT is a fundamental problem in Computer Audition and Music Information Retrieval and has been studied for several decades. However, the results are still behind the capabilities of a trained musician and unsatisfactory for practical purposes. Even the best algorithms cannot match human performance, and the transcribed pieces normally contain a large number of errors, in the form of wrong notes or missing notes. AMT has several applications in music education, such as helping music students in self checking their auditory skills, or helping amateur musicians by generating music scores that would be impossible to obtain otherwise. AMT systems could also be incorporated in more complex programs to help piano students during their practice. Beginner piano students need constant supervision during their practice, as they might not be able to recognize errors while they practice a new piece, yet having constant supervision by a music teacher is impractical and too expensive. An AMT system could be used to record and transcribe a piece performed by a student, and a separate component could be used to compare the performance with the original score, highlighting the performance errors.
Our approach
Our approach is based on a technique called Convolutional Sparse Coding (CSC), which has been successfully applied to several computer vision problems. CSC aims to reconstruct a signal (a digitized image or a digital music recording) by combining small elements called atoms. We use individually recorded notes from a piano as atoms, and CSC tries to reconstruct the performance by identifying the notes that have been played and by patching the corresponding atoms together at the right time. We call this a supervised approach, as it requires a training stage before the method can be used to perform a transcription. The training process takes only three minutes to record all the notes of a piano played one at a time. Our supervised approach can achieve very high precision in transcription, compared to other state-of-the-art systems.
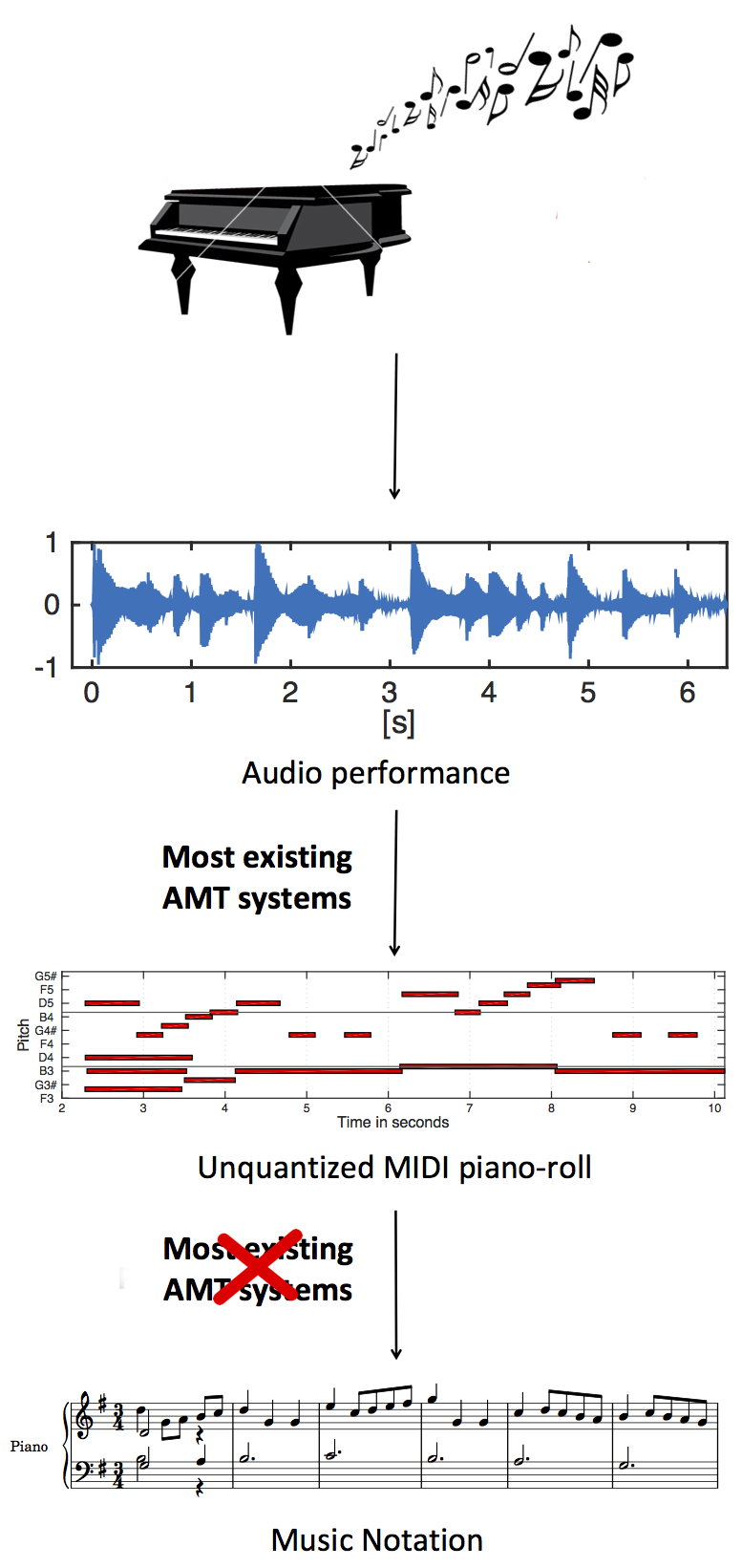
Going beyond existing AMT systems
The result after this stage, which is where most existing AMT systems stops, is what we call an unquantized piano roll. It means that we have identified all the correct notes and the time at which they were played, expressed in seconds. However, musicians are not used to think about music in terms of absolute time. Rhythm in music is expressed in terms of multiples or submultiples of a regular beat, which is regulated by a time signature (3/4, 4/4, and so on). Note spelling is also important to make the score more readable and avoid too many accidentals, but there is some ambiguity, as the same piano note can be notated in several different ways. For instance, the black key between an F and a G can be called an F sharp or a G flat. To be able to generate a music score we have to identify the rhythm of the piece, its time signature, its key; then we have to quantize the notes to the beats and determine the proper spelling. We can do that by using a probabilistic model that incorporates some music knowledge, thus mimicking the thought process of a musician.
Objective evaluation of music notation output
An immediate problem arising when building a music notation transcription system is to find an appropriate way to evaluate the transcription accuracy of the system. To assess the performance of the music notation output illustrated in the previous section we asked music theorists to evaluate the transcriptions. However, subjective evaluation is time consuming and difficult to scale to provide enough feedback to further improve the transcription system. It would be very helpful to have an objective metric for music notation transcription. Considering the inherent complexity of music notation, such a metric would need to take into account all of the aspects of the high-level musical structures in the notation. So we propose an edit distance, based on similar metrics used in bioinformatics and linguistics, to compare a music transcription with the ground-truth score. The design of the metric was guided by a data-driven approach and by simplicity. The metric is calculated in two stages. In the first stage, the two scores are aligned based on the pitch content; in the second stage, the differences between the two scores are accumulated, taking into account twelve different aspects of music notation: barlines, clefs, key signatures, time signatures, notes, note spelling, note durations, stem directions, groupings, rests, rest duration, and staff assignment. Finally, we apply a linear regression model to the errors measured by the metric to predict human evaluations of transcriptions.
Link to details of this project.
Publications
Andrea Cogliati and Zhiyao Duan, A metric for Music Notation Transcription Accuracy, in Proc. of International Society for Music Information Retrieval Conference, 2017, pp. 407-413.
Andrea Cogliati, Zhiyao Duan, and Brendt Wohlberg, Piano Transcription with Convolutional Sparse Lateral Inhibition, IEEE Signal Processing Letters, vol. 24, no. 4, pp. 392-396, 2017.
Andrea Cogliati, Zhiyao Duan, and Brendt Wohlberg, Context-dependent piano music transcription with convolutional sparse coding, IEEE/ACM Trans. Audio Speech Language Process, vol. 24, no. 12, pp. 2218-2230, 2016.
Andrea Cogliati, David Temperley, and Zhiyao Duan, Transcribing human piano performances into music notation, accepted by International Society for Music Information Retrieval Conference (ISMIR), 2016, pp. 758-764.
Andrea Cogliati, Zhiyao Duan, Brendt Wohlberg, Piano Music Transcription with Fast Convolutional Sparse Coding, accepted by IEEE International Workshop on Machine Learning for Signal Processing (MLSP), 2015, pp. 1-6.
Andrea Cogliati and Zhiyao Duan, Piano music transcription modeling note temporal evolution, in Proc. IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2015, pp. 429-433.