Music Rhythmic Analysis
This project encompasses multiple research papers, each addressing issues related to music rhythmic analysis. This post provides an overview of each paper, as outlined below:
1- Don't Look Back: An Online Beat Tracking Method Using RNN and Enhanced Particle Filtering
2- BeatNet: CRNN and Particle Filtering for Online Joint Beat Downbeat and Meter Tracking
3- A Novel 1D State Space for Efficient Music Rhythmic Analysis
4- Singing Beat Tracking With Self-supervised Front-end and Linear Transformers
5- SingNet: A Real-Time Singing Voice Beat and Downbeat Tracking System
6- BeatNet+: Real-Time Rhythmic Analysis for Diverse Music Audio (Under Process)
Don't
Look Back: An Online Beat Tracking Method Using RNN and Enhanced Particle
Filtering:
Problem:
Online beat tracking (OBT) presents challenges due to the
inaccessibility of future data and the necessity for real-time inference.
Approach:
Our proposed solution, Don't Look Back! (DLB), optimizes OBT
efficiency. DLB leverages a unidirectional RNN and an enhanced Monte-Carlo
localization model, using current time frame activations for beat position
inference.
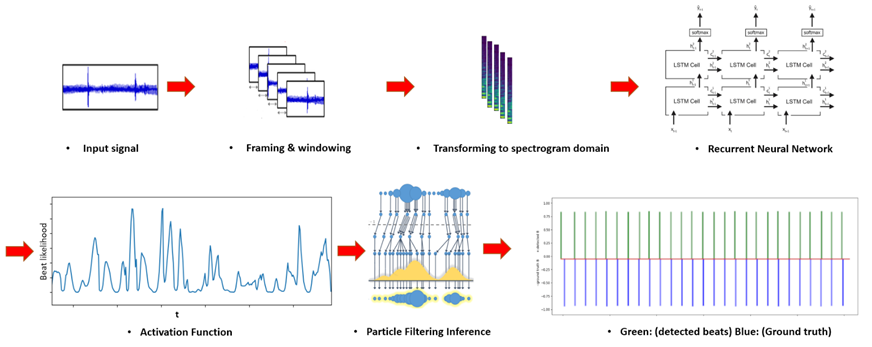
Fig. 1: Don't Look Back Model Overview Including Preprocessing, RNN and Particle Filtering Blocks
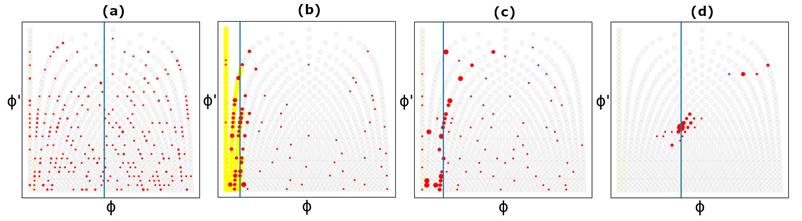
Fig. 2: Don't Look Back PF Inference Process: (a) Random particle initialization (b) Beat-boundary particles gain weight; others discarded with strong beat activation. (c) Particles Proceed forward. (d) Surviving the swarm with correct tempo and phase. Blue line: particle median Inferred positions.
Results:
DLB significantly
improves beat tracking accuracy over state-of-the-art OBT methods, yielding a
similar performance to offline methods.
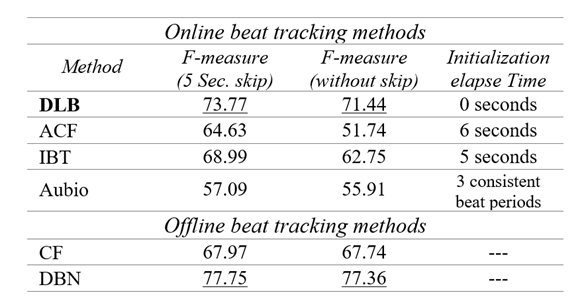
Table 1: F-measure report of online/offline beat tracking models and initialization time for online models (GTZAN dataset)
Related Links:
Paper Video Tutorial
*******************************************************************************************************************
BeatNet:
CRNN and Particle Filtering for Online Joint Beat Downbeat and Meter Tracking:
Problem:
Real-time estimation of rhythmic information, including beat
and downbeat positions, and meter, is crucial for numerous music applications.
The intricate hierarchical relationships in musical rhythm pose challenges, as
the analysis is inherently complex and subjective.
Approach:
This work introduces an online system for joint beat,
downbeat, and meter tracking. Leveraging causal convolutional and recurrent
layers, the system employs sequential Monte Carlo particle filters during
inference. Notably, it operates without the need for priming with a time
signature for downbeat tracking, dynamically estimating meter and adjusting
predictions over time. An information gate strategy is proposed to
significantly reduce the computational cost of particle filtering during
inference, enhancing system speed.
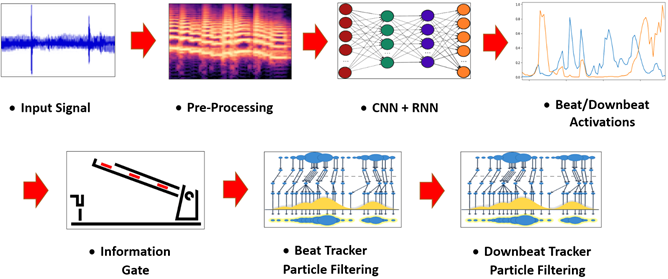
Fig. 3: BeatNet Pipeline
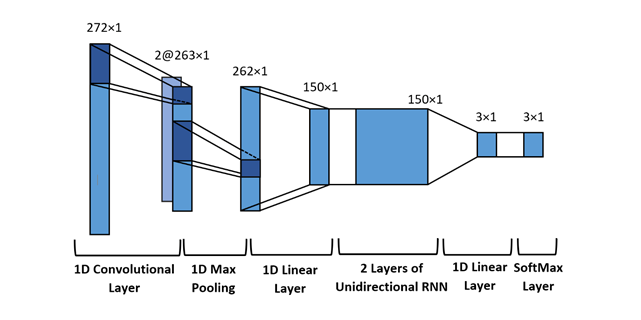
Fig. 4: BeatNet CRNN Neural Structure

Results:
Experiments on the unseen GTZAN dataset demonstrate the
system's superiority over various online beat and downbeat tracking systems.
Notably, it achieves performance comparable to a baseline offline joint method,
showcasing its effectiveness in real-time rhythmic information estimation.
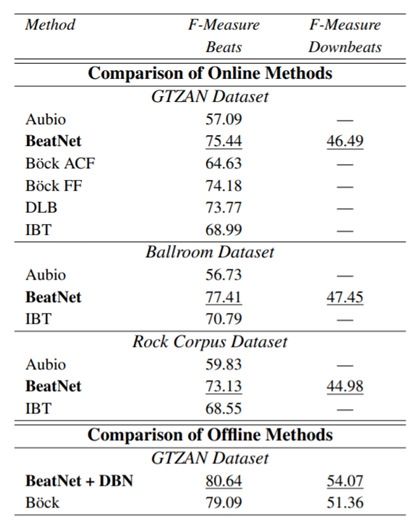
Table 2: F-measure report of online/offline beat/downbeat tracking models on 3 datasets
Paper Links:
Paper Video Tutorial
Paper Arxiv (PDF)
GitHub Source
*******************************************************************************************************************
A
Novel 1D State Space for Efficient Music Rhythmic Analysis:
Problem:
Music time structure analysis faces computational hurdles with state-of-the-art (SOFA) methods being impractical for real-world industrial settings.
Approach:
Introducing a new state space and semi-Markov model, we use a jump-back reward strategy to transform 2D state spaces into a 1D model, drastically reducing computational complexity.
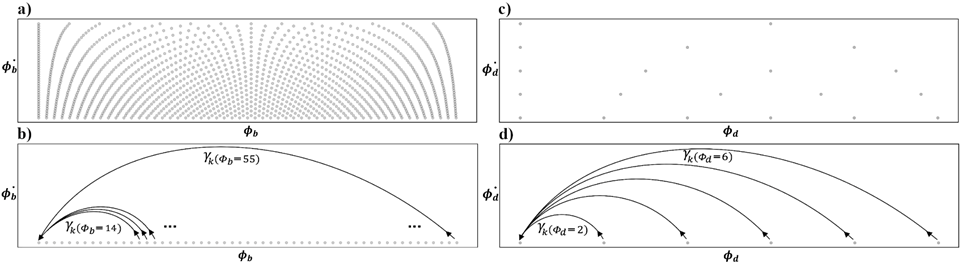
Fig. 5: Comparison Between traditional state spaces and the proposed 1D state space with Jump reward for beat (a and b) and downbeat (c and d) tracking
Results:
Our proposed method matches SOFA joint causal models' performance with over 30 times speedup, making it highly applicable to large music collections in industrial scenarios.
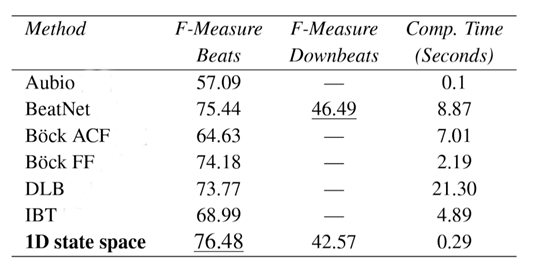
Table 3: System Performance and Speed Comparison between the proposed model vs previous SOTA
Paper Links:
Paper Video Tutorial
Paper Arxiv (PDF)
GitHub Source
*******************************************************************************************************************
Singing
Beat Tracking with Self-supervised Front-end and Linear Transformers:
Problem:
Singing voice beat tracking encounters difficulties due to the absence of strong rhythmic and harmonic patterns.
Approach:
This paper pioneers singing beat tracking, leveraging pre-trained self-supervised WavLM and DistilHuBERT speech representations, with a self-attention encoder layer for beat prediction.
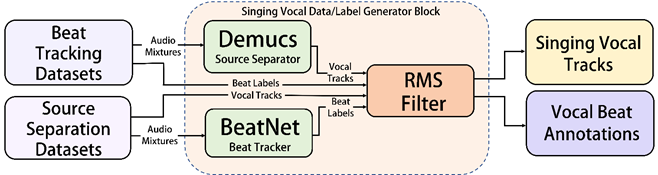
Fig. 6: Singing data and label generation pipeline.
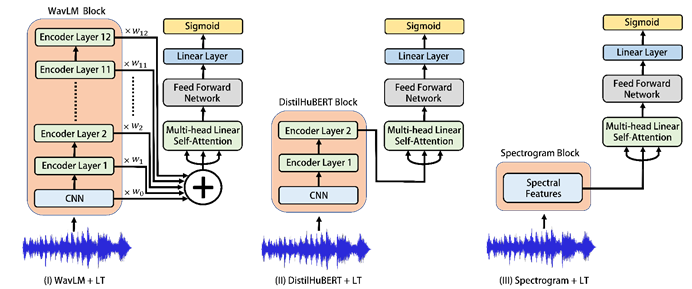
Fig. 7: Neural network structures of the proposed models. (I), (II) and (III) use WavLM, DistilHuBERT and Spectrogram front-ends blocks, respectively, followed by the same linear transformer network.
Results:
Experiments demonstrate the proposed system outperforming state-of-the-art methods by a significant margin in beat tracking accuracy.
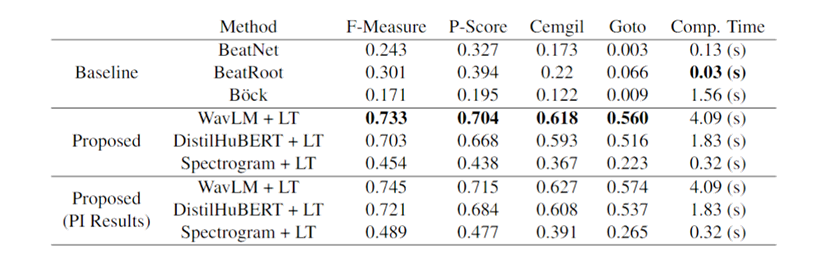
Table 4: Average performance and speed across segments of several methods on the GTZAN separated vocal tracks.
Paper Links:
Paper Video Tutorial
Paper Arxiv (PDF)
GitHub Source
*******************************************************************************************************************
SingNet:
A Real-Time Singing Voice Beat and Downbeat Tracking System:
Problem:
Real-time singing voice beat and downbeat tracking face
challenges, including non-trivial rhythmic patterns and the impossibility of
correcting inconsistent results.
Approach:
Introducing the first real-time system, our dynamic particle
filtering approach uses offline historical data for online inference correction
with a variable number of particles.
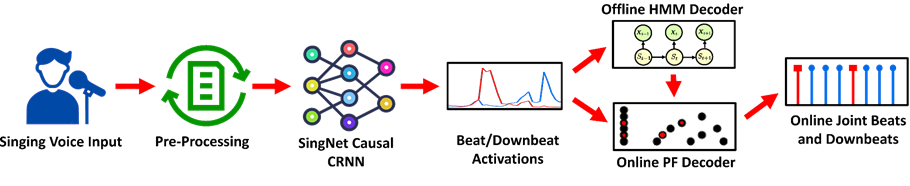
Fig. 8: Pipeline of the SingNet system
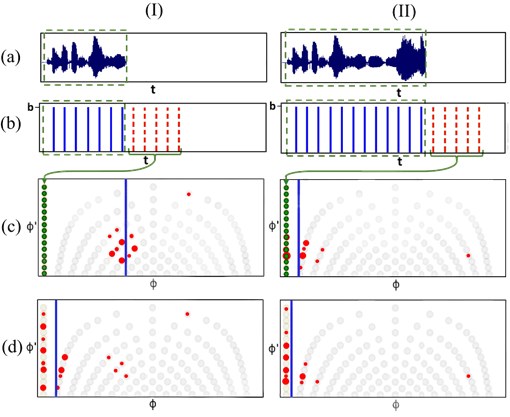
Fig. 9: Example of past-informed process for two time steps (I) and (II): (a) streaming audio arrival; (b) solid blue lines represent historical beats inferred by offline DBN, with dotted red lines as extrapolations; (c) injecting new particles (in green) into beat/tempo state space before resampling; (d) phase correction after resampling.
Results:
Experimental results show our approach outperforms the baseline by 3�5%, marking a significant advancement in real-time singing voice beat and downbeat tracking.
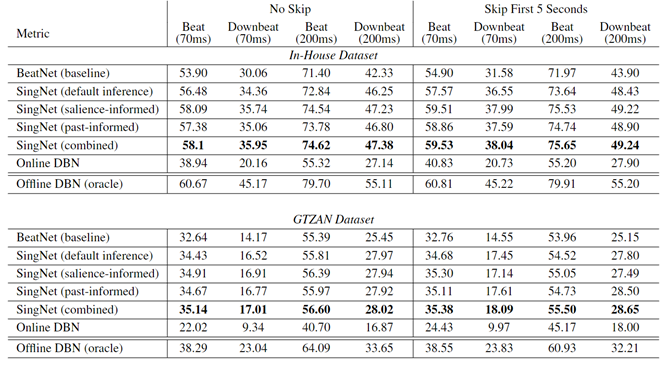
Table 5: Evaluation results (F1 scores in %) of different methods of SingNet and comparing them to the baseline models.
Paper Links:
Paper Video Tutorial
*******************************************************************************************************************