When Counterpoint Meets Chinese Folk Melodies
|
This project is supported by the National Science Foundation grant No. 1846184, titled “Human-Computer Collaborative Music Making". |
Motivation

Counterpoint, as an important and unique concept in Western music theory, refers to the mediation of two or more musical voices into a meaningful and pleasing whole. Chinese folk melodies, on the other hand, are typically presented in a monophonic form or with accompaniments that are less melodic. Many composers have made attempts to integrate counterpoint with Chinese folk melodies, however, systematic theories and broader influences on the general public are still lacking. This motivates our work.
Task
In this paper, we propose a system named FolkDuet to automatically generate countermelodies for Chinese folk melodies, modelling the counterpoint concept in Western music theory while maintaining the Chinese folk style. FolkDuet is designed to support real-time human-machine collaborative duet improvisation, hence the algorithm is causal.

Challenges
This task is not straightforward. We face two difficulties.
- First, Chinese folk melodies are mostly monophonic, hence supervisely training a counter melody generator directly from Chinese folk melodies is impossible.
- Second, counterpoint patterns are not easy to model. There do exist some publically available Western counterpoint datasets such as the Bach chorale dataset, however, it is not an easy task to model counterpoint patterns from them while removing other styles (e.g., melodic) in Western music.
Our solution is to use reinforcement learning. Reinforcement learning does not require labeled data! We only need to design task-specific reward functions. In our task, we need to model two reward functions, from preserving the Chinese folk style perspective and promoting the counterpoint interaction perspective. In particular, we model the degree of counterpoint interaction through a mutual information informed measure.
FolkDuet
Framework
The framework of FolkDuet is as follows: It contains a generator and two rewarders. The inter-rewarder models the counterpoint interaction in Western music, while the style-rewarder models the melodic pattern of Chinese folk songs. The generator is trained using reinforcement learning using these two rewards.
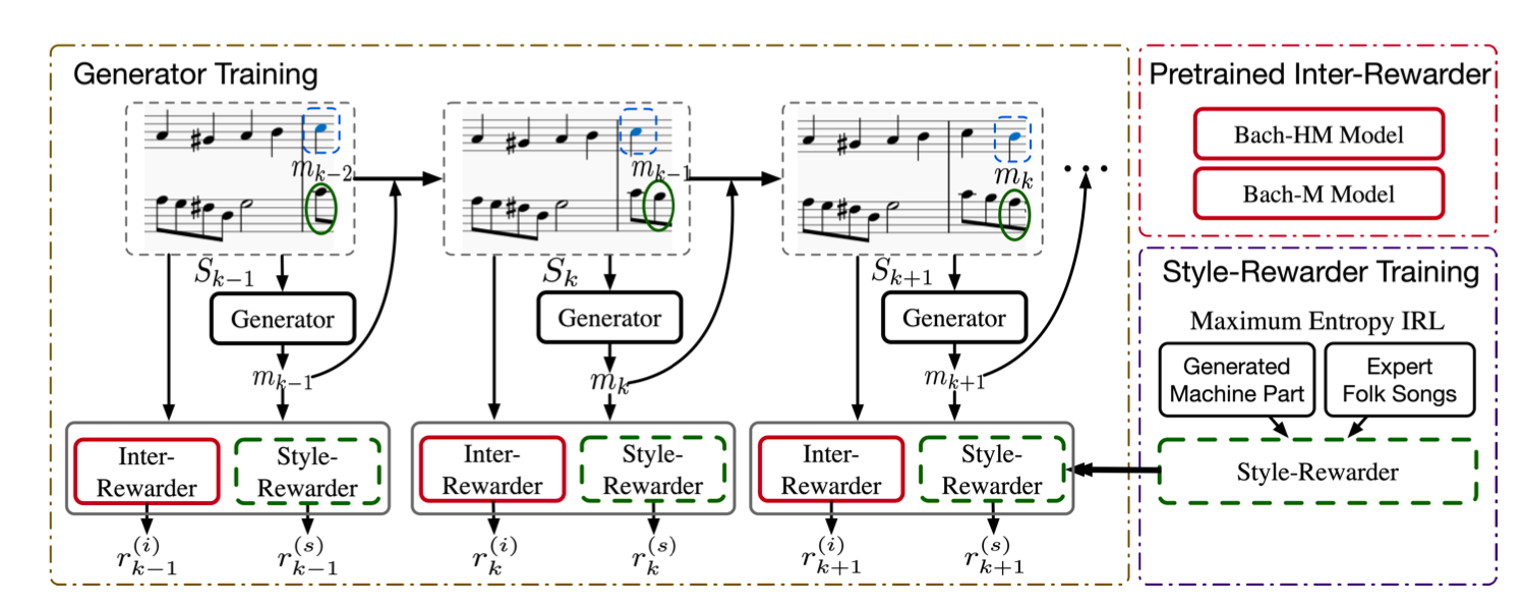
Generator
The generator generates the next note using its policy. Its training objective is to maximize the expected long-term discounted reward. The reward is a weighted sum of the style-reward and inter-reward. The long-term discounted reward of note makes the generator look into future, taking the global coherence of the whole music into consideration.
Style-Rewarder
The style-rewarder is alternatively updated using the maximum entropy inverse reinforcement learning. Inverse reinforcement learning (IRL) is an algorithm to infer a reward function underlying the demonstrated expert behavior, i.e. the Chinese folk dataset. IRL and RL are usually trained alternately, such that the reward function could be dynamically adjusted to suit the reinforcement learning process. As there are no existing data of Chinese folk duets, the Style-Rewarder is trained using the monophonic Chinese folk melodies and the generated machine part by the generator.
Inter-Rewarder
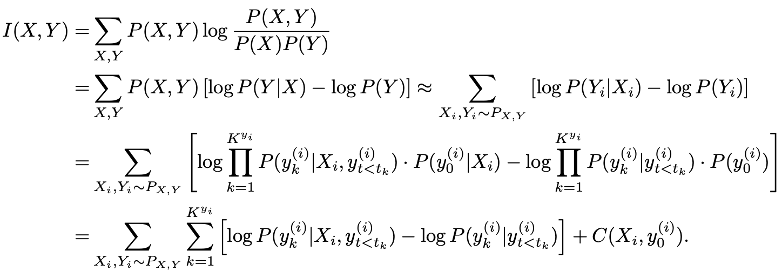
The inter-rewarder measures the degree of interaction between human and machine parts through a mutual information informed measure. In the above derivation, X and Y represents the human part and the machine part respectively. The mutual information between these two parts could be decomposed into the sum of a constant C and the difference between two log-probabilities. We pretrain two models, Bach-HM and Bach-M models, using the Bach chorale dataset, and the inter-reward is defined as the difference between log P(Machine|Human) and log P(Machine). In plain English, it encourages the generator to generate countermelodies that achieve a good interaction with the human part (i.e., larger log P(Machine|Human)), while discouraging the orginal Bach style (i.e., lower log P(Machine)).
Results
We compare FolkDuet with two baselines.
- The first baseline is a maximum likelihood estimation (MLE) model trained on our transposed outer parts of Bach chorales. This model needs to be trained on duets hence cannot be trained on the monophonic Chinese folk melodies in our training set.
- The second baseline is a pre-trained model RL-Duet, which is our recently proposed reinforcement learning algorithm for online duet counterpoint harmonization, without considering the Chinese folk style.
We compare the performance of FolkDuet and the two baselines on counter melody generation for the Chinese folk melodies.
Can interaction reward reflect counterpoint interaction?
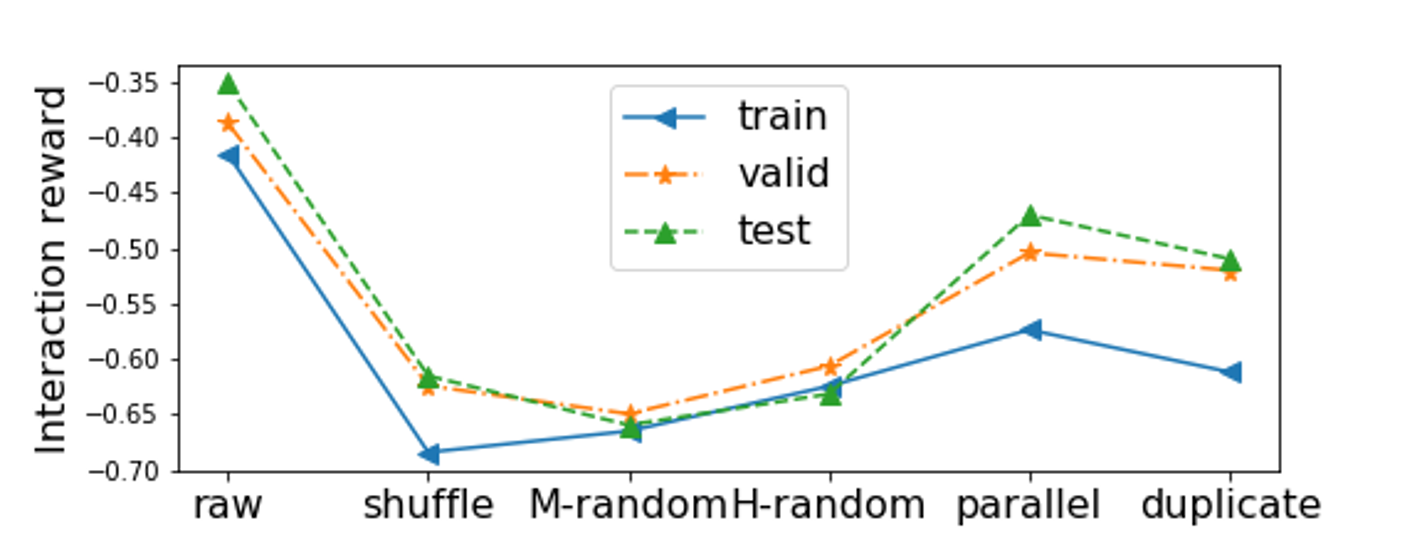
To validate that the inter-reward can reflect counterpoint interaction, we calculate this reward on several kinds of the duets constructed from the outer parts of Bach chorales, including original duets (raw), duets of two randomly shuffled parts (shuffle), duets with random notes in the machine part (M-random), duets with random notes in the human part (H-random), duets of parallel human and machine parts (parallel), and duets of duplicated parts (duplicate). This figure shows that this interaction reward achieves the highest score on the original duets.
Objective Results
To measure how well the Chinese folk style is preserved, we use objective metrics suggested in "On the evaluation of generative models in music." For PC/bar, PI, IOI. We show the statistics calculated on the test dataset and on the generated music by each algorithm, and their differences. For PCH and NLH, we calculate the earth moving distance between the statistics on the test dataset and the generated music by each algorithm.
- PC/bar: pitch count per bar
- PI: average pitch interval
- IOI: average inter-onset interval
- PCH: pitch class histogram.
- NLH: note length histogram.

To measure the interaction between the two parts of a duet, we adopt two simple metrics. One is the average key-consistency, which is defined as the cosine similarity of the pitch class histograms of the two parts. The other is the interaction reward used to train the generator. Objective results show that the generation from FolkDuet is closer to the Chinese folk dataset and it achieves better key consistency with the human part.
Subjective Results
We also conducted a paired subjective evaluation. Each subject was presented with a pair of two duet excerpts with the same human part. These two duets came from FolkDuet and MLE model. RL-Duet was excluded, since we observed some apparently bad generations of RL-Duet. Its Bach style is so strong that its generated parts differ sharply from the folk melodies. Subjectives' preferences with their background are shown in these two figures. In total, 160 people participated in the survey and 1,177 music pairs were compared and scored. On average each pair was scored by 6.4 subjects.
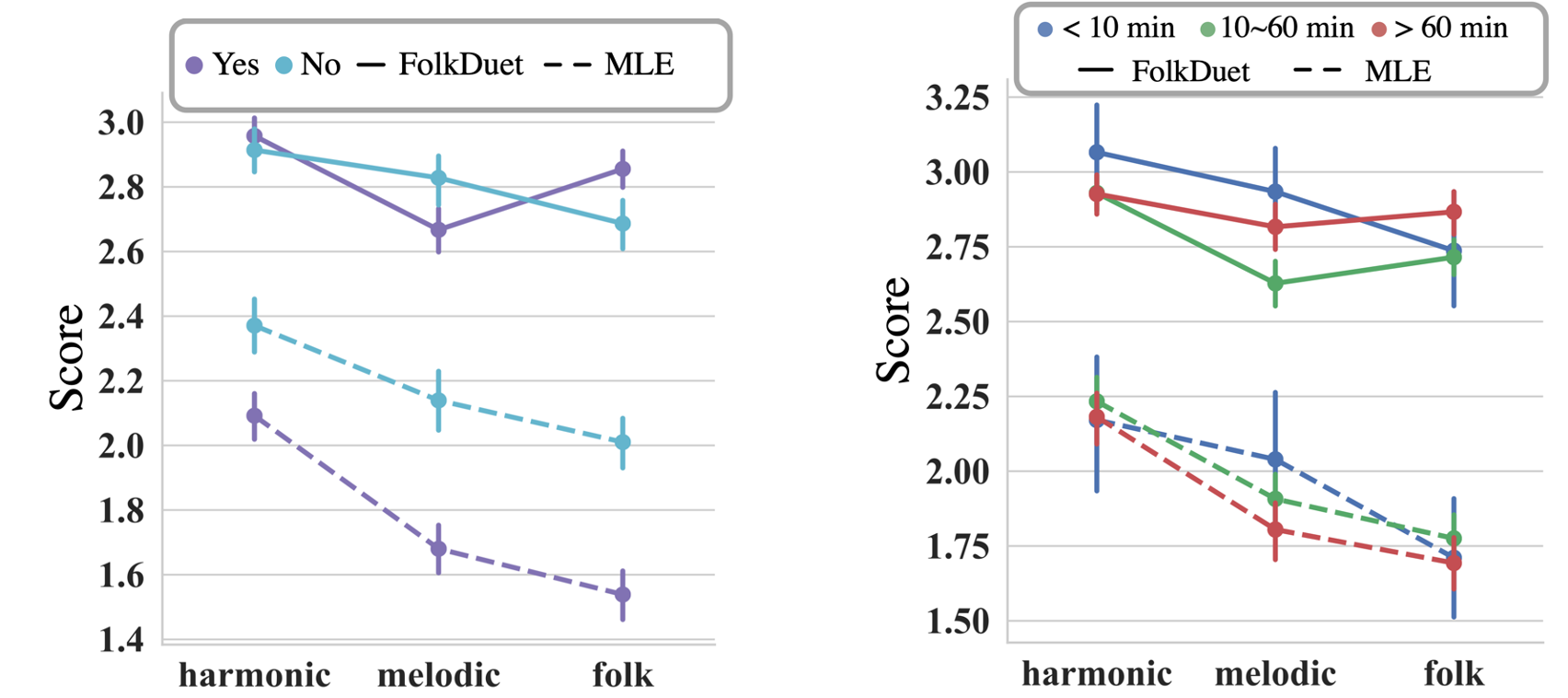
Subjects background:
- Yes: had music training/background before
- No: had no music training/background before
- <10 min: spent less than 10 minutes everydat to listen to music
- 10-60 min: spent 10~60 minutes everydat to listen to music
- >60 min: spent more than 60 minutes everydat to listen to music
Evaluation perspectives:
- Harmonic: harmonic appealingness of the duets
- Melodic: melodic appealingness of the generated part
- Folk: prominence of the Chinese folk style of the generated part
Examples
The generated countermelody is highlighted in red. We use the first 10 notes in the human part as the initialization of the machine part, by transposing these notes either 12 semitones above or below. Above or below was randomly chosen such that the pitch range does not exceed the pitch range of the dataset.
Example 1

Example 2

Example 3

Subjective listening tests give FolkDuet higher scores than the baseline along all of the three aspects, especially for subjects with some music background.
Improving Cadence Generation
The above examples are contained in our original paper. After the paper acceptance, we further improved our model by taking the music cadence into consideration. In our previous version, the model has no idea that when the human will stop his/her improvisation. So sometimes we observed that when the human part comes to termination, the generated machine part still shows some sign of continuation. After this improvement, the machine part knows when and how to end the generation!
Example 1

Example 2

Example 3

Publication
Nan Jiang, Sheng Jin, Zhiyao Duan, and Changshui Zhang, When counterpoint meets Chinese folk melodies, accepted by The Thirty-fourth Conference on Neural Information Processing Systems (NeurIPS), 2020. <code>