Learning Sparse Analytic Filters for Piano Transcription
Frank Cwitkowitz, Mojtaba Heydari, and Zhiyao Duan
Motivation
The goal of this project was to explore the efficacy of filterbank learning for low-level music information retrieval tasks such as automatic music transcription. Here, filterbank learning corresponds to replacing the standard feature extraction stage, where features such as Mel-Spectrogram or the Constant-Q Transform (CQT) are typically employed, with a bank of learnable complex filters.
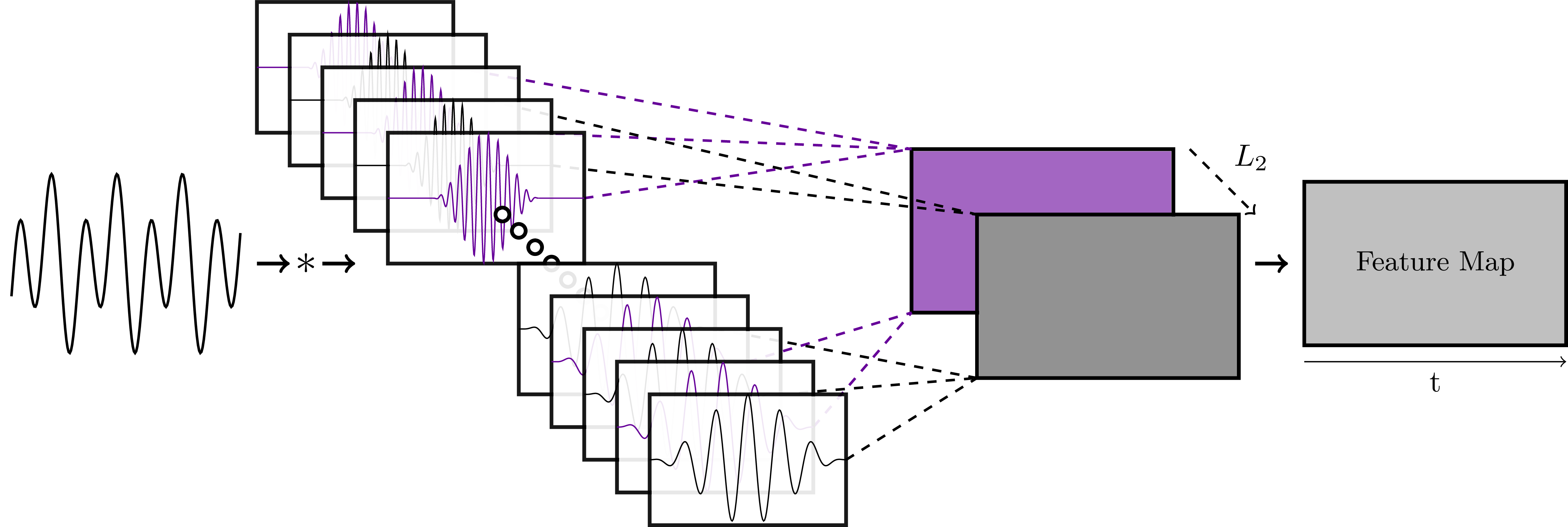
In the classic filterbank learning approach, complex filters are typically represented as two separate 1D convolutional filters corresponding to the real (black) and imaginary (purple) parts. Audio is fed directly into each of the filters, and L2 pooling is applied to the grouped responses to compute the magnitude response for each complex filter.
Proposed Method
In addition to the classic filterbank learning approach, we experimented with various extensions to learn frontend filters for the Onsets & Frames piano transcription model. We used the MAESTRO dataset for training, validation, and testing, and we also evaluated models on the MAPS dataset.
- The first extension consisted of learning only the real part of each filter, and computing the imaginary part directly using the Hilbert transform, such that the resulting complex filters were analytic. Analytic filters are more desirable than strictly real or non-analytic complex filters, since they exhibit shift invariance, much like the complex filters employed in standard transforms like the CQT.
- The second extension consisted of applying variational dropout to filters during training, treating their weights as random variables with learned variance. This regularization technique led to filters with more modularity, interpretability, and a higher degree of sparsity, properties which are important for filterbank learning.
Several different filterbank initialization strategies were also investigated to see what kind of impact initialization had on the filterbank learning process. These strategies include random initialization, Variable-Q initialization, and harmonic comb initialization.
Results
In general, the learned filterbanks did not outperform standard time-frequency representations like the Mel-Spectrogram or CQT as frontends for piano transcription. However, the gap in performance between models trained jointly with the learned filterbanks and those trained with the standard features was quite small. Futhermore, one suprising result is that the filterbanks initialized randomly only fell slightly behind those initialized with the Variable-Q strategy.
The following figures illustrate some of the filters learned as a result of the experiment with random initialization where both filterbank learning extenensions (Hilbert transform and variational dropout) were applied.
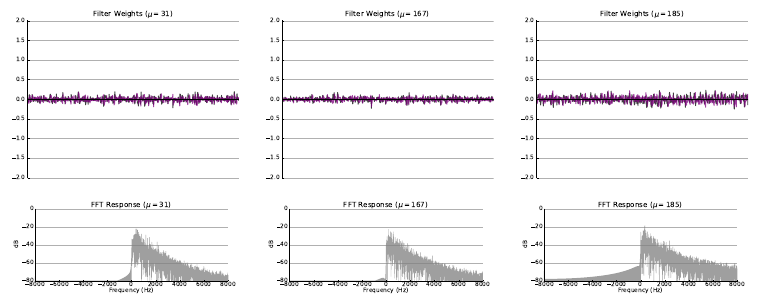
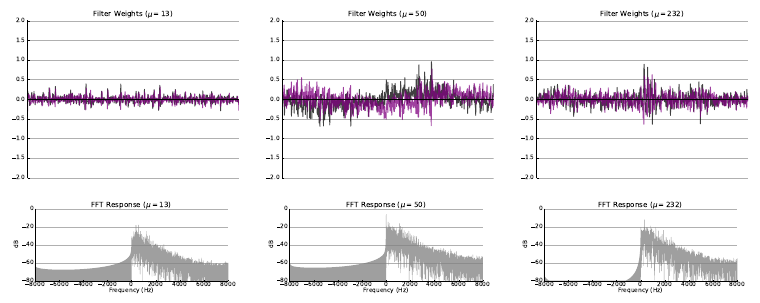
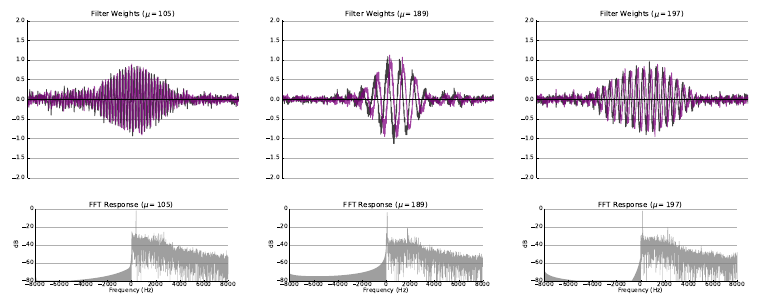
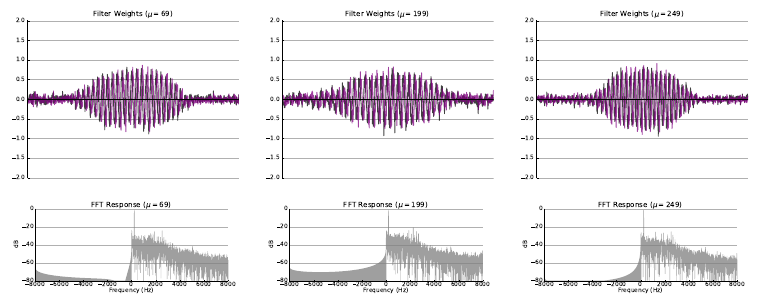
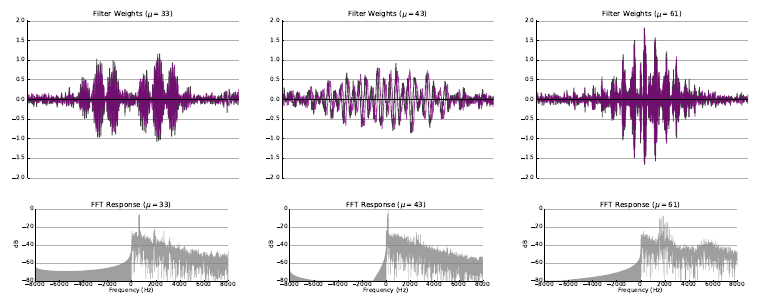
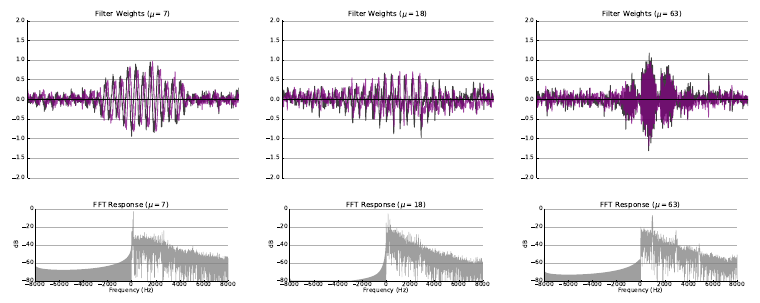
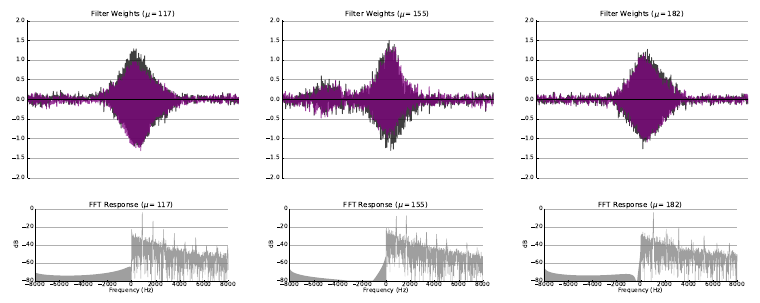
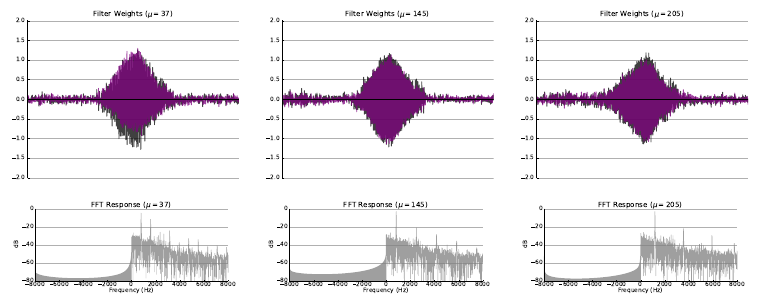
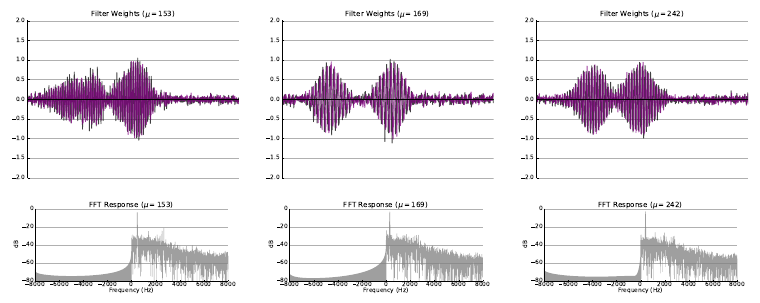
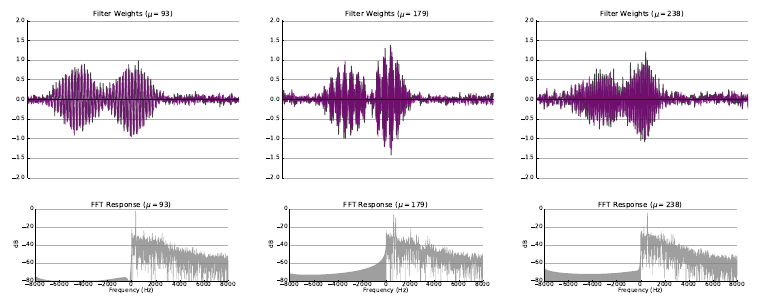
Please refer to the arXiv Version of the paper to view more examples of learned filters for each experiment.
Publications
Frank Cwitkowitz, Mojtaba Heydari, and Zhiyao Duan, Learning Sparse Analytic Filters for Piano Transcription, in Proc. The Sound and Music Computing Conference (SMC), 2022, pp. 209-216.
Additional Resources
Acknowledgments
This work has been funded by the National Science Foundation grants IIS-1846184 and DGE-1922591. We would also like to thank Dr. Juan Cockburn and Dr. Andres Kwasinski for their guidance during preliminary work.