Generating Talking Face Landmarks from Speech
|
This project is supported by the National Science Foundation under grant No. 1741472, titled "BIGDATA: F: Audio-Visual Scene Understanding". |
What is the problem?
The visual cues from a talker's face and articulators (lips, teeth, tongue) are important for speech comprehension. Trained professionals are able to understand what is being said by purely looking at lip movements (lip reading) [1]. For ordinary people and the hearing impaired population, the presence of visual signals of speech has been shown to significantly improve speech comprehension, even if the visual signals are synthetic [2]. The benefits of adding the visual speech signals are more pronounced when the acoustic signal is degraded, due to background noise, communication channel distortion, and reverberation.
In many scenarios such as telephony, however, speech communication is still acoustical. The absence of the visual modality can be due to the lack of cameras, the limited bandwidth of communication channels, or privacy concerns. One way to improve speech comprehension in these scenarios is to synthesize a talking face from the acoustic speech in real time at the receiver's side. A key challenge of this approach is to make sure that the generated visual signals, especially the lip movements, well coordinate with the acoustic signals, as otherwise more confusions will be introduced.
In this project, we developed methods to generate 2D and 3D talking face landmarks from (noisy) speech. This webpage includes lots of demos of the generation results.
2D landmark generation
What is our approach?
We propose to use a long short-term memory (LSTM) network to generate landmarks of a talking face from acoustic speech. This network is trained on frontal videos of 27 different speakers of the Grid audio-visual corpus, with the face landmarks extracted using the Dlib toolkit The network takes the first- and second-order temporal differences of the log-mel spectra as the input, and outputs the x and y coordinates of 68 landmark points. To help the network capture the audio-visual coordination instead of the variation of face shapes across different people, we transform all training landmarks to those of a mean face across all talkers in the training set. After training, the network is able to generate face landmarks from an unseen utterance of an unseen talker.
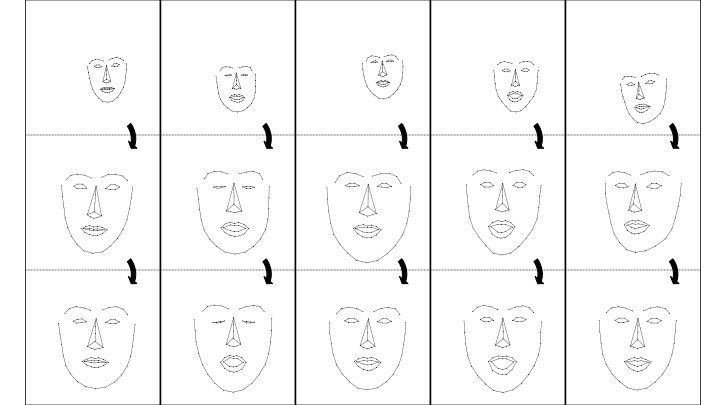
Our Results
The following examples are generated from Librispeech test samples.
Subjective Evaluation
We conducted subjective tests to determine if our system can generate realistic face landmarks. 17 naive subjects who are graduate students at the University of Rochester participated in the test. The test presented 25 real landmark videos and 25 generated landmark videos in a randomized order to each subject and asked the subject to label whether each presented video was real or fake. Fake videos were generated from the audio signals of another 25 randomly selected LDC videos. In addition to a binary decision, the subjects were also asked to report their confidence level of each decision, between 0 and 100 percent.
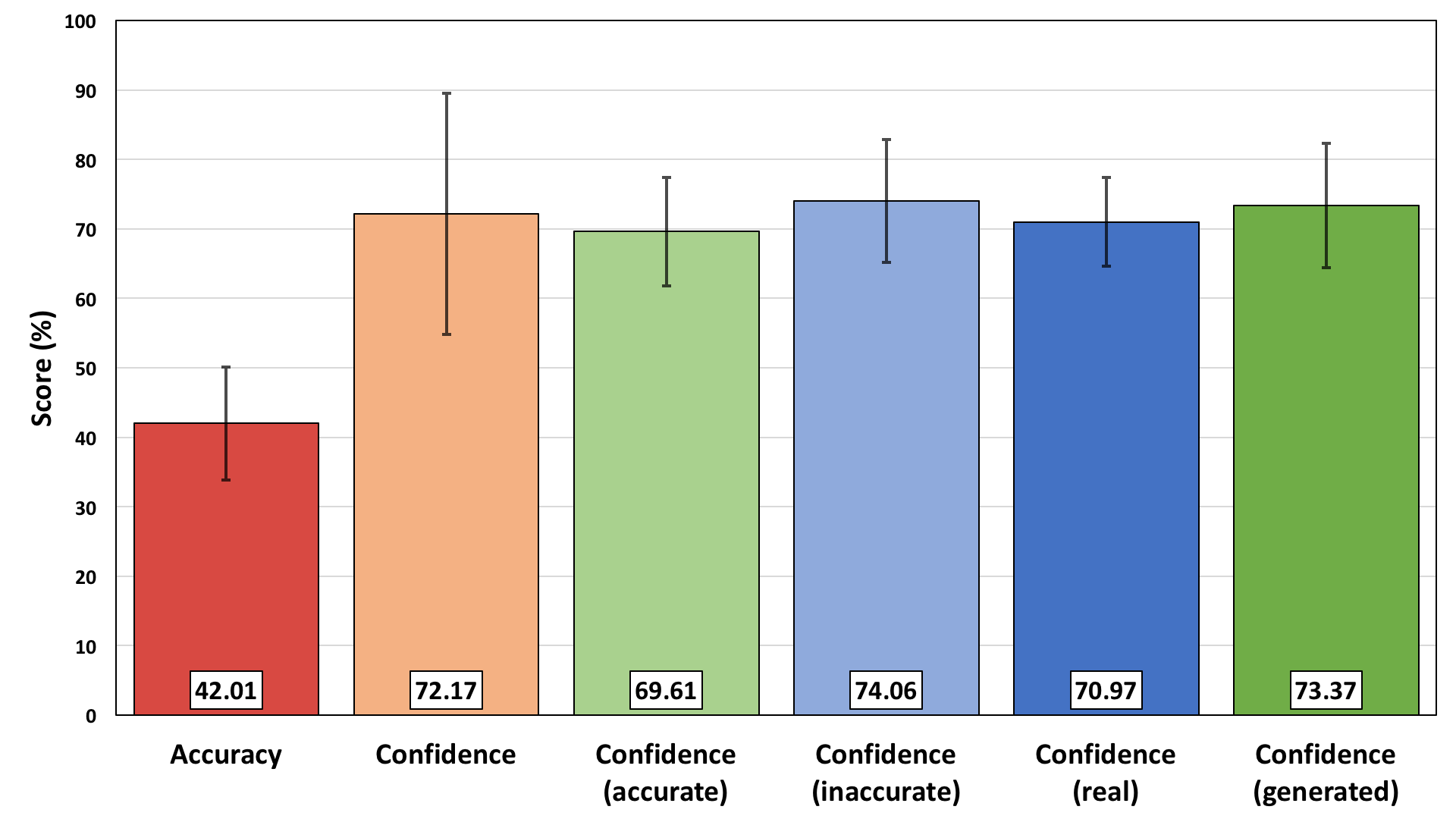
The mean accuracy score of the participants are shown in Figure 2, along with the overall mean confidence score and the mean confidence score for the correctly and incorrectly predicted samples. The results show that the participants struggled to distinguish real and generated samples, as the accuracy is 42.01% which is even below chance (50%).
Test It Yourself
You can download the pre-trained talking face models and offline generation code from here.3D landmark generation
What is our approach?
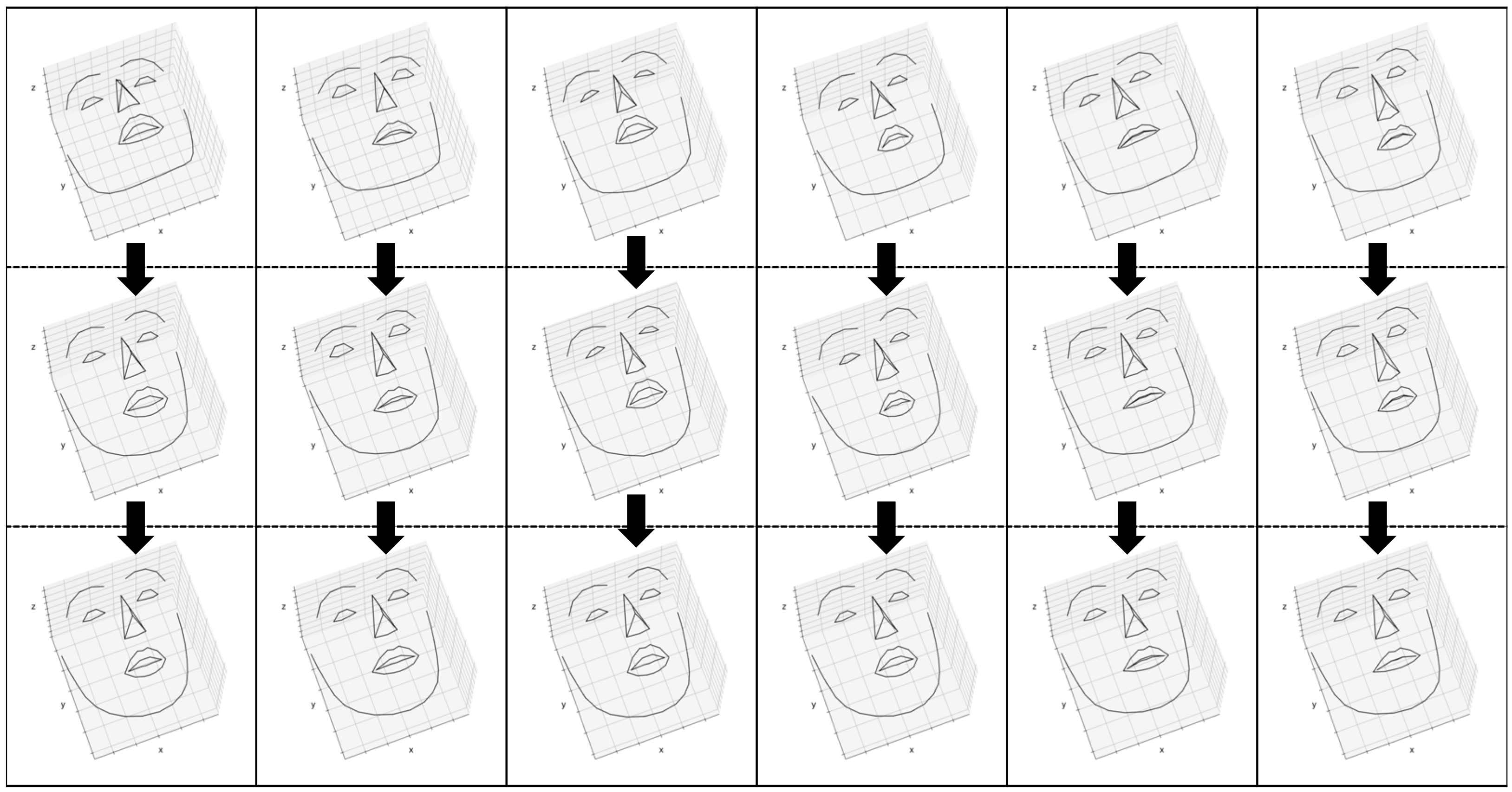
Our Results
The following examples are generated from unseen speech samples. The left column shows the results for 1D_CNN model, and the right column shows the results for 1D_CNN_TC model.
Timit Samples
1D_CNN
1D_CNN_TC
VCTK Samples
1D_CNN
1D_CNN_TC
Noise Analysis
The following examples are generated from noisy speech. The left column shows the results for 1D_CNN model, and the right column shows the results for noise resilient model, namely 1D_CNN_NR.
9 dB Signal-to-Noise Ration (SNR)
1D_CNN
1D_CNN_NR
Babble Noise
Factory Noise
Speech-Shaped Noise
Motorcycle Noise
Cafeteria Noise
Comparison with Ground-Truth (GT) Landmarks
The following videos contain both ground-truth landmarks (black lines) and the generated landmarks using 1D_CNN model (red_lines). The samples are from STEVI corpus.
Publications
Sefik Emre Eskimez, Ross K. Maddox, Chenliang Xu, and Zhiyao Duan, Generating talking face landmarks from speech, in Proc. International Conference on Latent Variable Analysis and Signal Separation (LVA/ICA), 2018. <pdf> <poster> <code>
Sefik Emre Eskimez, Ross Maddox, Chenliang Xu, and Zhiyao Duan, Noise-resilient training method for face landmark generation from speech, IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 28, pp. 27-38, 2020. <pdf>
References
[1] Dodd, Barbara Ed, and Ruth Ed Campbell, “Hearing by eye: The psychology of lip-reading,” The psychology of lip-reading Lawrence Erlbaum Associates, Inc, 1987.
[2] Maddox, Ross K., et al., “Auditory selective attention is enhanced by a task-irrelevant temporally coherent visual stimulus in human listeners,” Elife 4 2015.