Draw and Listen! A Sketch-based System for Music Inpainting
Christodoulos Benetatos and Zhiyao Duan
|
This project is supported by the National Science Foundation under grant No. 1846184, titled " CAREER: Human-Computer Collaborative Music Making". |
🎵 New Interactive Demo 🎵
Excited to share our latest demo! Try it here 🎨🎶
System Description
We proposed a system for interactive musical inpainting. This system allows users to draw pitch and optional note density curves to guide the pitch contour and rhythm of the generated melodies.
The core of our system is based in a new melody disentanglement scheme that decomposes a melody to the following factors :
\begin{equation} \begin{aligned} Melody \ = \ &relative \ \ pitch \\ \oplus \ &pitch \ \ offset\\ \oplus \ &relative \ \ rhythm\\ \oplus \ &rhythm \ \ offset \\ \oplus \ &context. \end{aligned} \end{equation}
The user's input curves control the relative pitch (green curve) and the relative rhythm (blue curve) factors. We also provide two sliders for the user to control the pitch and rhythm offsets. The remaining context factor is estimated from the surrounding measures.
When the first 4 factors of the equation are 'precise', then the context factor is not needed to infer the melody. The more 'vagueness' we add to the first 4 factors, the more important the role context becomes in reconstructing the melody. Thus, by controling this tradeoff we can determine the amount of influence that the user's curves have over the final result. Please check our paper for more details
Motivation - Applications
Previous work on music inpainting either does not support user interaction, or assumes users to know some music theory in order to achieve musically meaningful results. Our goal is to design a system that engages users into the music inpainting process without assuming a musical background.
A system like this:
- Can be used as a composition plugin for music notation editors or midi editors inside a DAW
- Can support other creative applications by replacing the hand drawn curves with anything that resembles a curve, such as a stock price curve or a human body movement curve.
- Can be used to measure melodic similarity and query a melody database by converting melodies in the latent space and calculating their latent vector distances based on any of the disentangled factors (relative pitch or rhythm)
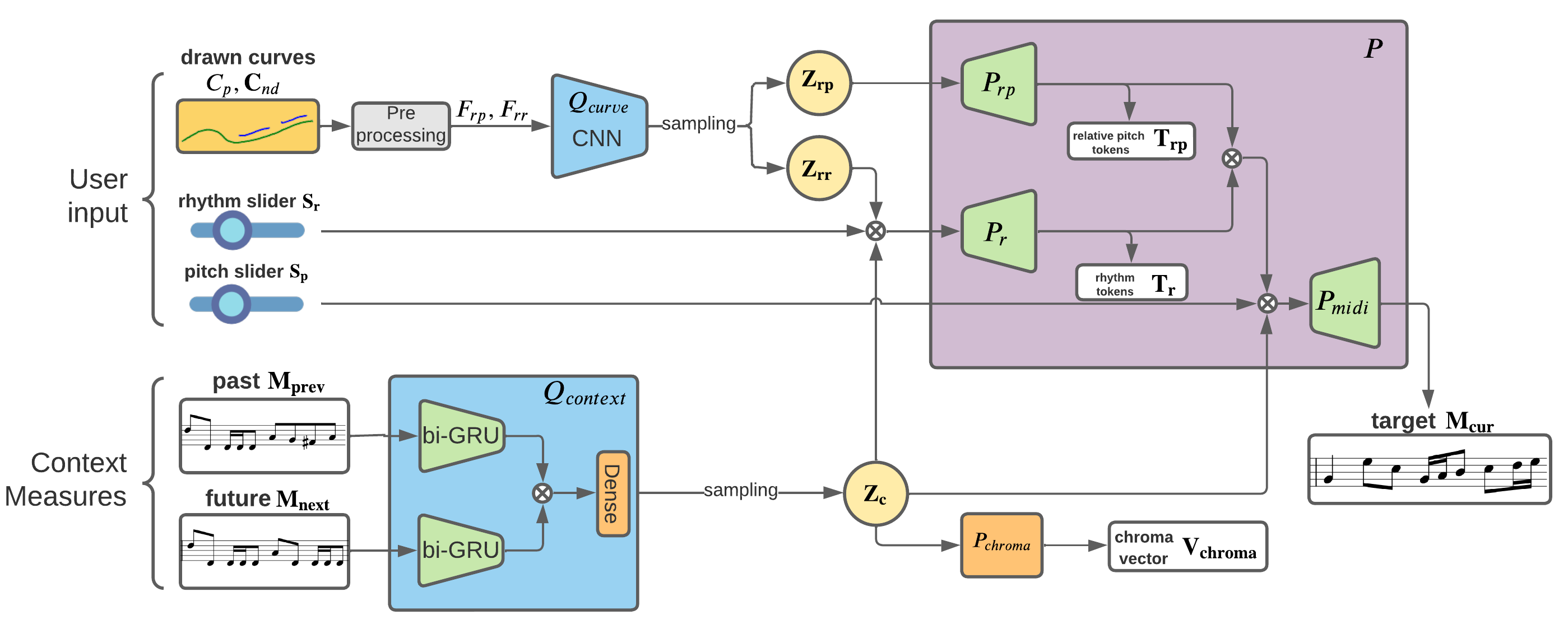
Model Architecture
The model we propose is a variational auto-encoder (VAE) based architecture. As shown on the left side of the figure, we have two encoders, \(Q_{curve}\) and \(Q_{context}\), to process the user's input and the context measures, respectively. The encoders' output forms the VAE's latent vector is \(Z = [Z_{c} ; Z_{rp} ; Z_{rr}]\), i.e., a concatenation of three vectors, where \(Z_{c}\) stores the context information, \(Z_{rp}\) stores the relative pitch information, and \(Z_{rr}\) stores information about the relative rhythm. On the right side, we use three decoders, \(P_{rp}\), \(P_r\), and \(P_{midi}\), with different intermediate losses to achieve the desired disentanglement of the three latent variables.
Results
We conduct both objective and subjective evaluations to assess the feasibility and usability of the proposed system for drawing-based melody inpainting. We compare it with two closely related methods as baselines under the same user interface and we show that our model achieves better performance. For the objective evaluations and details on the baseline algorithms please check our paper.
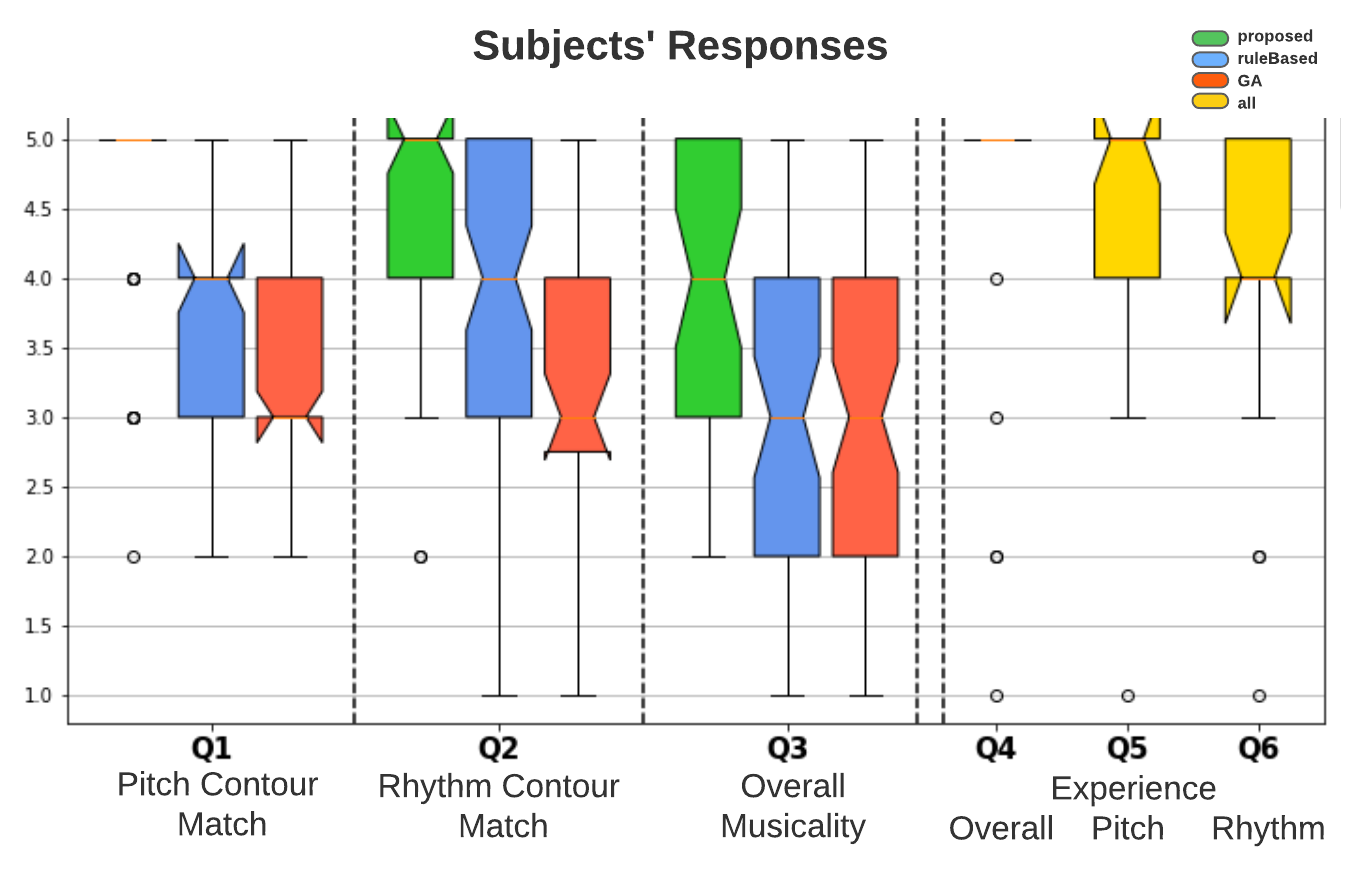
Subjective Evaluations
For this experiment, we developed a simple web-based interface which consists of a canvas area for a user to draw the curves with their mouse, and three same display areas for showing the same context measures and the generated results for each method (ours and two baselines). The assignment of methods to the display areas is randoized for every trial to reduce biases toward a specific method
We recruited 23 participants with various musical backgrounds and we got 112 trials in total(each trial consists of drawing a curve and generating the melodies using each of the 3 methods). We asked the participants to answer the following questions:
- Rate the similarity between the hand-drawn pitch curve and the generated pitch contour
- Rate the effect of the note density inputs (rhythm slider and note density curves) to the melody's rhythm.
- Rate the overall musicality of the final result.
- Do you think this system provided an intuitive way to generate a melody ?
- Do you think drawing a pitch curve is an intuitive way to control a melody's contour?
- Do you think drawing additional note density curves is an intuitive way to control a melody's rhythm?
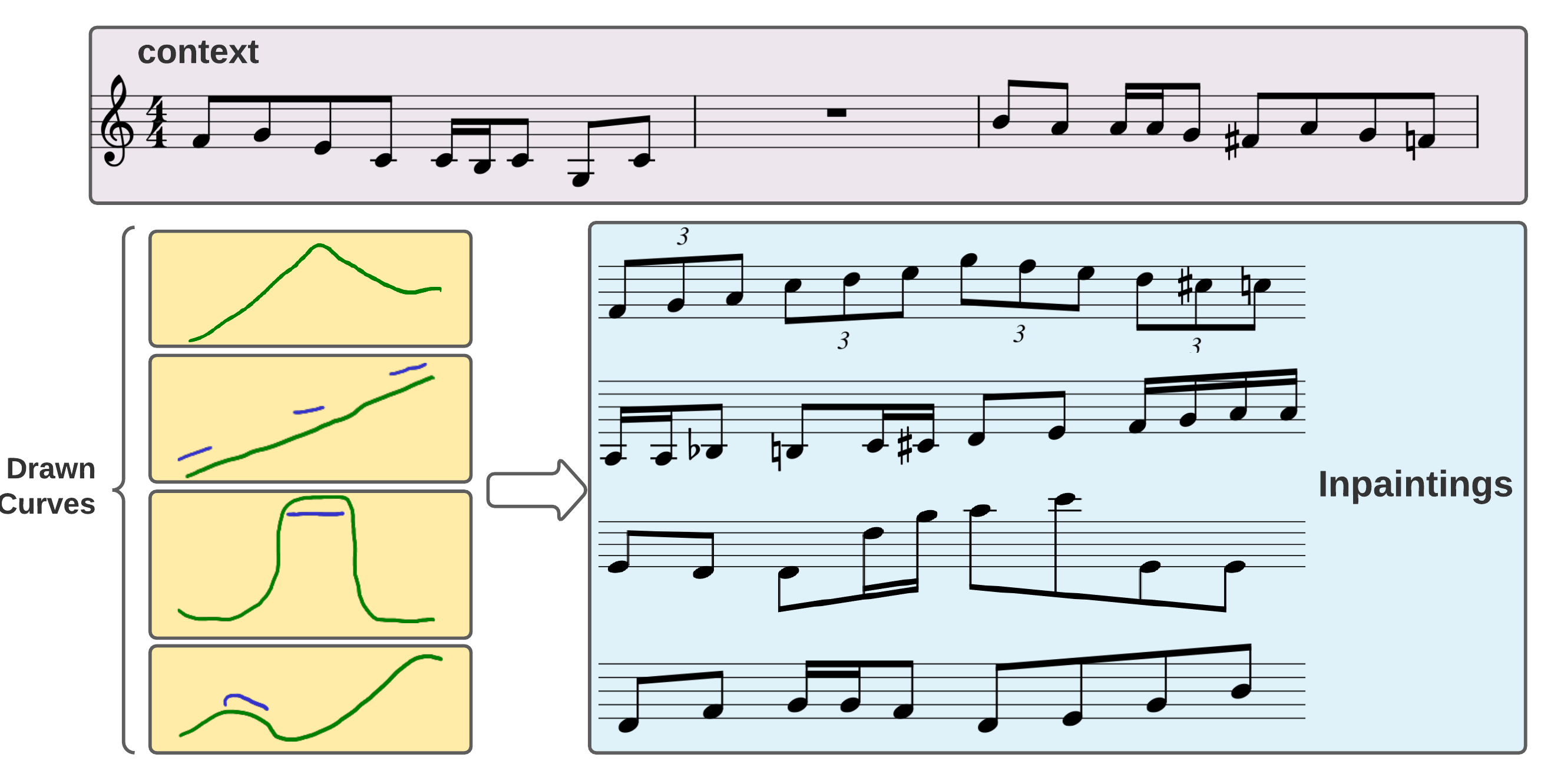
Examples
An example of 4 different input curves using the same context measures.
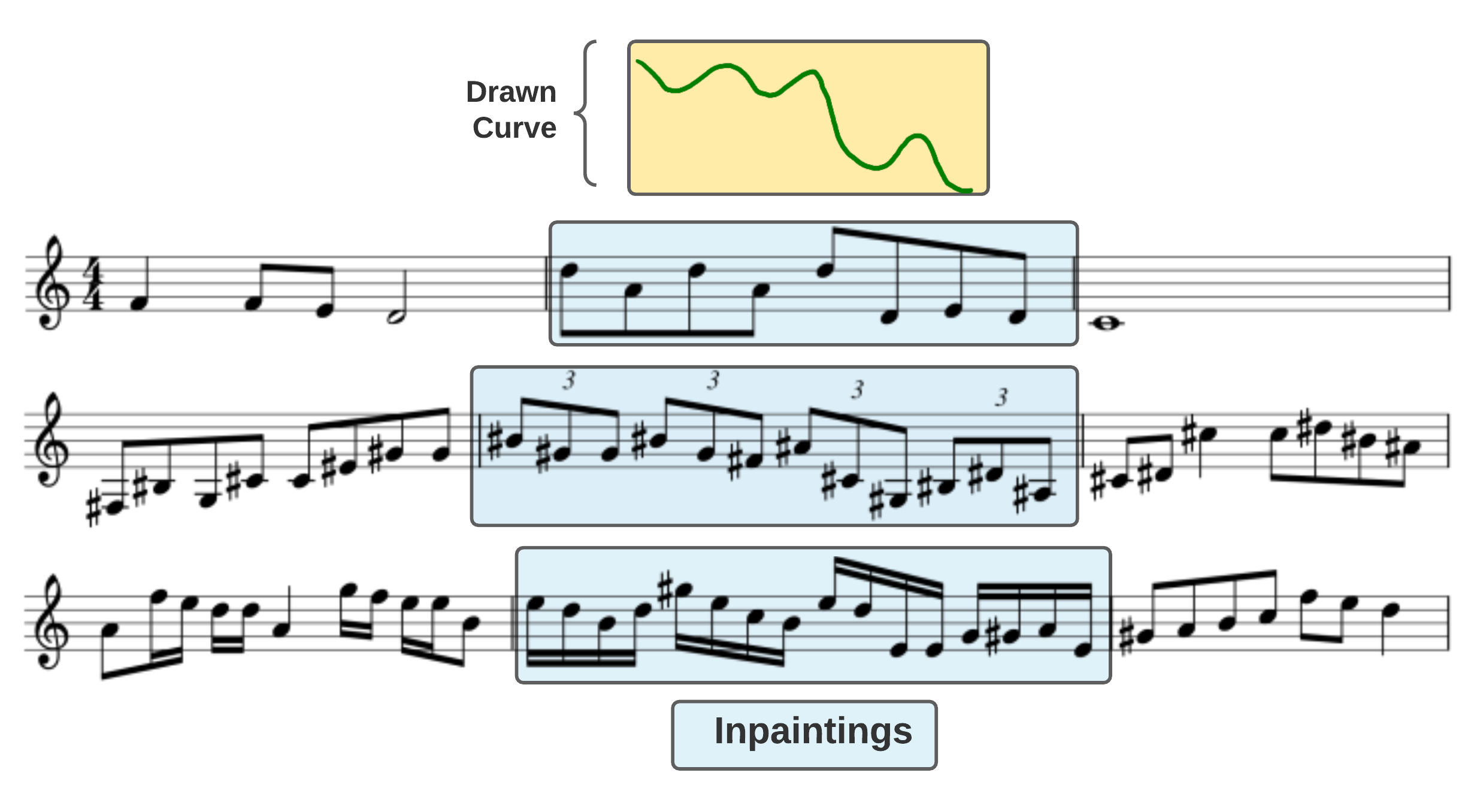
An example of one hand-drawn pitch curve working with three different context measures to generate different but context matching melodies.
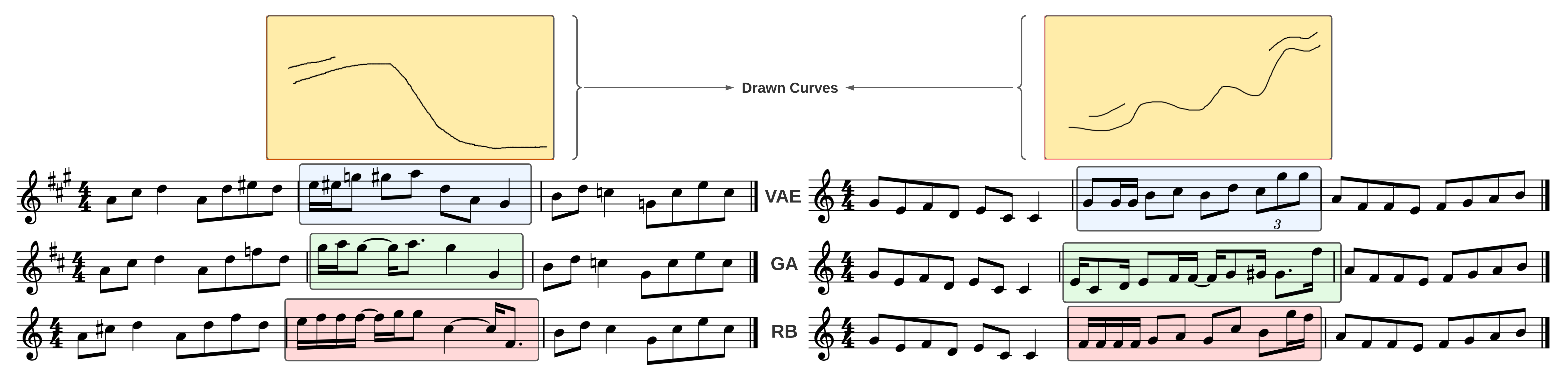
Two examples obtained during the user studies. The first line is the output of the proposed VAE model and the next two contain the baselines' ouputs.
Many more examples from all methods can be found here
Code
The code for this project is available on GitHub.
Publications
Christodoulos Benetatos and Zhiyao Duan, Draw and Listen! A Sketch-based System for Music Inpainting, in Transactions of the International Society for Music Information Retrieval (TISMIR), 2022.