Sound Search by Vocal Imitation
A Quick Glance
Below is a pre-recorded video for our paper titled "Vroom!: A Search engine for sounds by vocal imitation queries" presented at the 2020 Conference on Human Information Interaction and Retrieval (CHIIR) that introduces the Vroom! search engine and demonstrates how it works. For more detailed descriptions, please see the following sections.
Search Engine: Vroom!
We designed a web-based sound search engine by vocal imitation, called Vroom!, which can be accessed via https://vocalimitation.com. It includes frontend design and backend implementation.
The frontend GUI is designed using Javascript, HTML, and CSS. It allows a user to record a vocal imitation of sound that he/she is looking for from a certain category using the recorder.js Javascript library. It also allows the user to listen to the recording, inspect the waveform, and re-record imitations. By clicking on the ``Go Search!'' button, the user can initiate the search request. The recording is then uploaded to the backend server and compared with each sound within the specified category using the CR-IMINET algorithm described later. Top five sound candidates with the highest similarity scores are first returned to the user, and more candidates up to 20 can be returned by clicking on "Show more results". The user can play the returned sounds and make a selection to complete the search. Only sounds that have been played become available for the selection. If not satisfied with any of the returned sounds, the user can re-record an imitation and re-do the search. The frontend GUI is shown in Figure 1(a).
Hosted on a Ubuntu system, the backend server is designed using Node.js express framework, with Keras and GPU acceleration supported. It receives the user’s vocal imitation from the frontend, pre-processes the audio, then implements a Siamese style convolutional recurrent neural network model called CR-IMINET to calculate the similarity between the vocal imitation and candidate sounds in the sound library. It responds to each frontend search request and retrieves the most similar sounds to each imitation query, within the specified sound category of the sound library.
To evaluate the performance of the proposed Vroom! search engine, we also designed a web-based sound search engine by text description as the baseline system, called TextSearch.
Similar to Vroom!, the frontend GUI of TextSearch is designed using Javascript, HTML, and CSS languages as well. As shown in Figure 1(b), the GUI provides the user with a text box to enter one or multiple keywords as the query for a sound. The user can then click on the ``Go Search!'' button to search.
The backend is realized by designing a main server that receives and responds to requests from the frontend, and utilizing a separate search engine service called Solr specialized in text search and matching. The entire backend is hosted on a Ubuntu system. The overall process is as the following. The query request from the frontend users is first received by the main server. Then the main server resends query requests to Solr for text search and ranking. The ranked list is then returned to the main server from Solr, and finally returned to the frontend user.
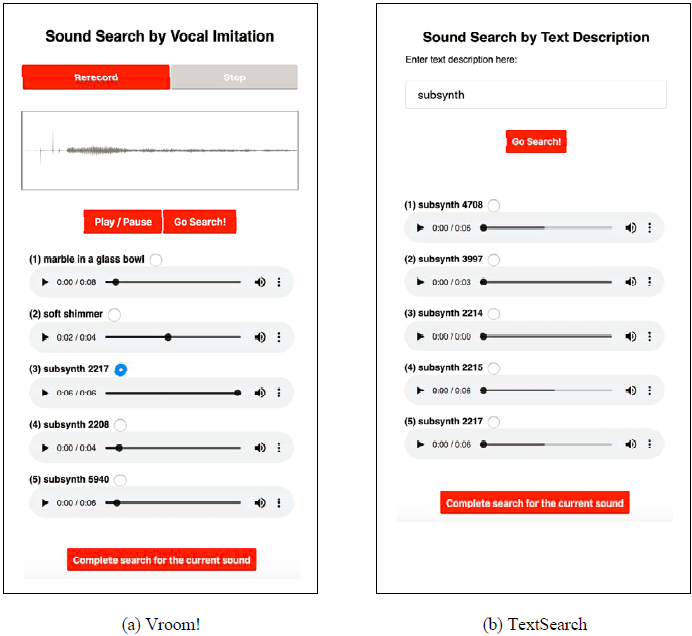
Figure 1. Frontend GUIs of (a) the vocal-imitation-based search engine Vroom! and (b) the text-based-search engine TextSearch}.
Dataset Collection: FreeSoundIdeas
To carry out the subjective evaluation, we create a new dataset called FreeSoundIdeas as our sound library. The sounds of this dataset are from Freesound.org, while we reference sound descriptions and the structure of how sounds are organized in Sound Ideas to form the FreeSoundIdeas ontology. Specifically, the ontology has a multi-level tree structure and is derived from two libraries of Sound Ideas: "General Series 6000 - Sound Effect Library" and "Series 8000 Science Fiction Sound Effects Library", where the former has more than 7,500 sound effects covering a large scope, and the latter has 534 sound effects created by Hollywood's best science fiction sound designers. We copied the indexing keywords from 837 relatively distinct sounds in these two libraries and formed eight categories of sound concepts, namely, Animal (ANI), Human (HUM), Music (MSC), Natural Sounds (NTR), Office and Home (OFF), Synthesizers (SYN), Tools and Miscellaneous (TOL), and Transportation (TRA).
We do not use sounds from Sound Ideas because of copyright issues, instead, we use keywords of each sound track from the abovementioned ontology as queries to search similar sound from Freesound.org. For each query, the first 5 to 30 returned sounds from Freesound.org are downloaded and stored as elements for our FreeSoundIdeas dataset. Keywords of these sounds from Freesound.org instead of the queried keywords to find these sounds are stored together with these sounds for a more accurate description. It is noted that this FreeSoundIdeas dataset has no overlap with the VimSketch dataset which is used to train the search algorithm for Vroom!.
In total the FreeSoundIdeas dataset includes 3,602 sounds. There are 230, 300, 521, 86, 819, 762, and 660 sound concepts in the category of ANI, HUM, MSC, NTR, OFF, SYN, TOL, and TRA, respectively. Its ontology is shown in Figure 2, with the Transportation category being expanded to leaf nodes to illustrate the granularity.
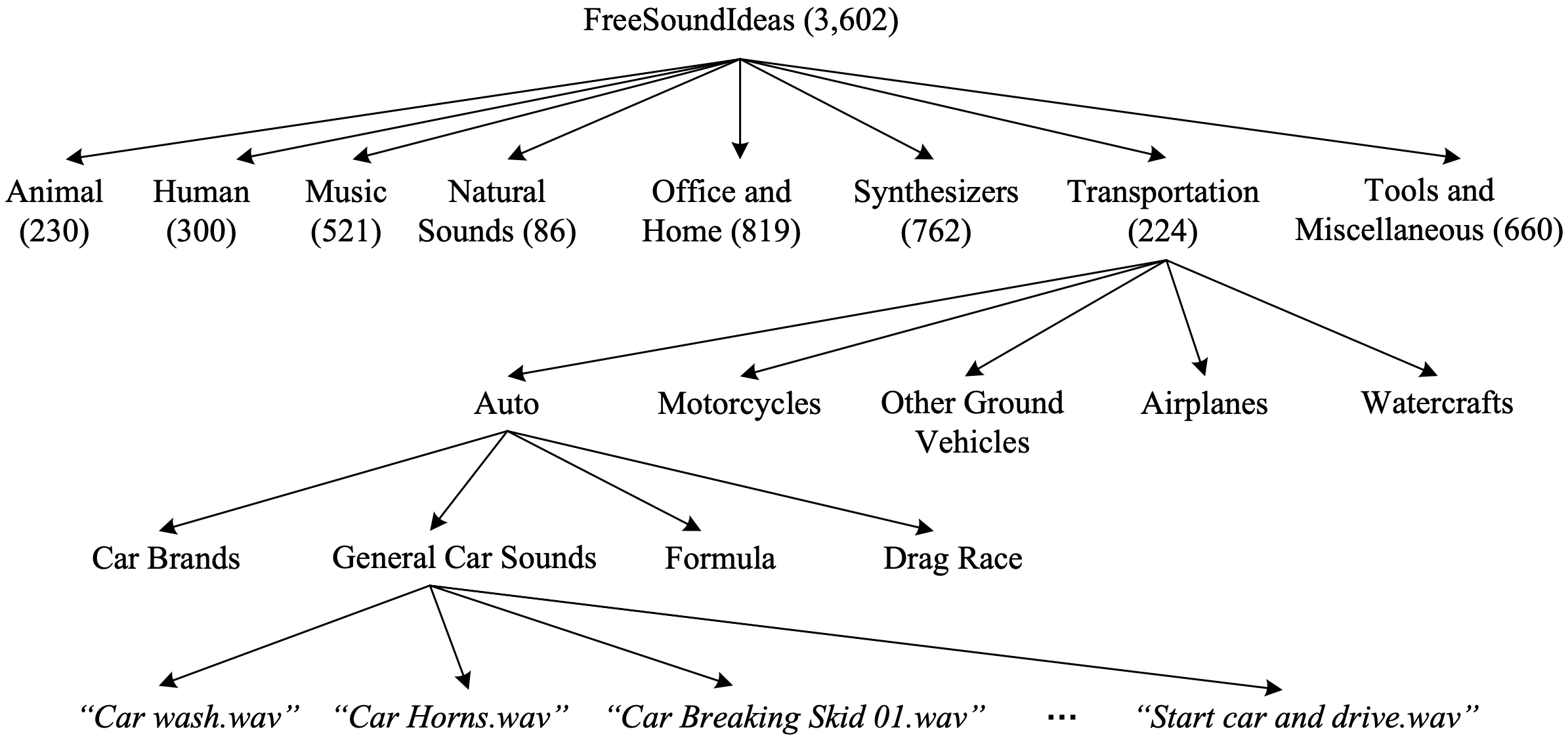
Figure 2. FreeSoundIdeas dataset ontology. Numbers in parentheses indicate the number of sound concepts in the category at the first level of the ontology tree.
Experimental Framework
To quantify search behaviors and user experiences and to make quantitative comparisons between Vroom! and TextSearch, we designed an experimental framework that wraps around each search engine. The experimental framework is another web application. The framework guides each subject to make 10 searches, rate their satisfaction score about each search, and rate the ease-of-use score for the search engine after completing all 10 searches. For each search, it guides the subject through three steps. In Step 1, the subject listens to a reference sound randomly chosen from a category of the sound library. The category name is visible while the keywords of the sound is not provided. This sound will be the target sound to search in following steps. In Step 2, the reference sound is hidden from the subject, and the subject uses the search engine (Vroom! or TextSearch) to search for the reference sound in the specified category of the sound library. In Step 3, the reference sound appears again. The user compares it with their retrieved sound to rate their satisfaction about the search. These three steps, for the Vroom! search engine, are shown in Figure 3 for illustration.
The experimental framework tries to mimic the search processes in practice as much as possible. For example, searches are conducted in each of the eight root categories instead of over the entire library to reduce complexity, as the root-level categories show clear distinctions on their semantics. However, certain modifications still have to be made to allow quantitative analysis. In practice, a user rarely listens to the exact target sound before a search; they usually only have a rough idea about the target sound in their mind to cast their query (imitation or text). In our experimental framework, however, before each search, the subject listens to the target sound to cast their query. While this may positively bias the quality of the query (especially for the imitation query), this is necessary to control what sound to search by the subjects. For example, the library may simply not contain the target sound if we allowed subjects to search freely. To reduce this positive bias, we hide the target sound during the search (Step 2).
The backend of this experimental framework records statistics of important search behaviors listed as the following. These statistics are then sent to MongoDB Atlas cloud database for storage and analysis.
- User satisfaction rating for each search
- Ease-of-use rating for the search engine
- Number of ``Go Search!'' button clicked
- Number of returned candidate sounds played
- Total time spent for each search
- Rank of the target sound in the returned list for each search

Figure 3. Experimental framework hosting the proposed vocal imitation based search engine Vroom!. The framework hosting the text description based search engine TextSearch is exactly the same except that Step 2 is replaced with the TextSearch engine.
Subject Recruitment
We recruited a total of 200 workers (i.e., 100 for each search engine) from the crowdsourcing platform Amazon Mechanical Turk (AMT) as our subjects. Our sound search tasks were released through cloudresearch.com as it provides several more advanced and convenient features compared with the task releasing mechanism in AMT. The demographic information of the recruited subjects is summarized in Figure 4. We can see that the gender distribution is quite even, and a large portion of subjects were born in the 1980s and 1990s. For race distribution, most subjects are White/Caucasian, followed by Black/African American and Asian.
The two groups of subjects were asked to perform 10 sound searches using Vroom! and TextSearch, respectively. Subjects were informed about the collection of their search behaviors and ratings before the experiments. After the user finished 10 sound searches and provided ease-of-use score and general feedback, then the completion code would be available for the user to paste into the text box from the task portal. Finally, we verified the submitted completion code from each subject to approve his/her job.
Our internal pilot trials show that each experiment took about 25 and 15 minutes for Vroom! and TextSearch, respectively. Therefore, we paid each subject $1.5 US dollars for Vroom! and $1 US dollar for TextSearch. To encourage the subjects to treat the experiments more seriously, we made an extra 50% bonus payment based on the worker's performance. Subjects were informed about this compensation policy including the bonus payment before they started the experiments.

Figure 4. Pie charts showing the demographic information of the subjects. Charts are created based on the information collected from cloudresearch.com. Please note that cloudresearch.com may not have every demographic for every subject.
Experimental Results
User Feedback
Figure 5 compares two types of user ratings between \emph{Vroom!} and \emph{TextSearch}: 1) User's satisfaction rating (SAT) indicates how satisfied a user is with each search by comparing the finally retrieved sound to the reference sound (collected in Step 3 in Figure \ref{Fig_ExperimentalFramework}); 2) ease-of-use rating evaluates a user's overall experience of each search engine upon the completion of all 10 searches.
Figure 5. Average user ratings of sound search by text description (TextSearch) and vocal imitation (Vroom!). Ratings include the overall ease-of-use rating of the two search engines, and search satisfaction (SAT) within each sound category and across all categories. Error bars show standard deviations.
It can be seen that Vroom! shows a statistically significantly higher ease-of-use rating than TextSearch at the significance level of 0.05 (p=0.0324, unpaired t-test). This suggests that vocal-imitation-based search can be accepted by ordinary users without an extensive audio engineering background. The average satisfaction rating of all categories shows slightly better performance of Vroom! than TextSearch. However, a further inspection reveals that the average satisfaction rating varies much from one category to another. For MSC, NTR, SYN, and TOL categories, Vroom! receives a statistically significantly higher satisfaction rating than TextSearch does, at the significance level of 0.1 (MSC p = 9.8e-2), 0.1 (NTR p = 6.1e-2), 0.001 (SYN p = 8.22e-10), and 0.1 (TOL p = 8.79e-2), respectively, under unpaired t-tests. This is because many subjects could not recognize sounds from these categories nor find appropriate keywords to search in TextSearch. This is especially significant for the SYN category, as many sounds simply do not have semantically meaningful or commonly agreeable keywords, while imitating such sounds was not too difficult for many subjects. Also please note that in conducting Vroom! experiments with AMT workers, TOL Category was named as a much boarder concept called "Sound of Things", while in TextSearch this category was renamed to the current "Tools and Miscellaneous" to provide more information and help the worker better understand the sounds they heard. This may slightly bias the experimental results to TextSearch in TOL category. Nevertheless, in the figure we see that Vroom! still outperforms TextSearch in TOL category in terms of user satisfaction rating. On the other hand, for the ANI, HUM, and OFF category, however, TextSearch outperforms Vroom! significantly in terms of satisfaction rating, at the significance level of 0.005 (ANI p = 1.2e-3), 0.005 (HUM p = 1.2e-3), 0.05 (OFF p = 2.1e-2), respectively, under unpaired t-tests. Subjects were more familiar with these sounds that can be easily identified in everyday environments and knew how to describe them with keywords, while some sounds could be difficult to imitate, e.g., shuffling cards, toilet flushing, and cutting credit card. For the remaining TRA category, the average satisfaction rating of TextSearch is slightly better than our proposed Vroom!, however, such outperformance is not statistically significant.
User Behavior
Figure 6 further compares user behaviors between Vroom! and TextSearch. First, for both search engines, it is obvious to observe the trend of positive correlation among the number of search trials, the number of sounds played, and the total time spend in one sound search.
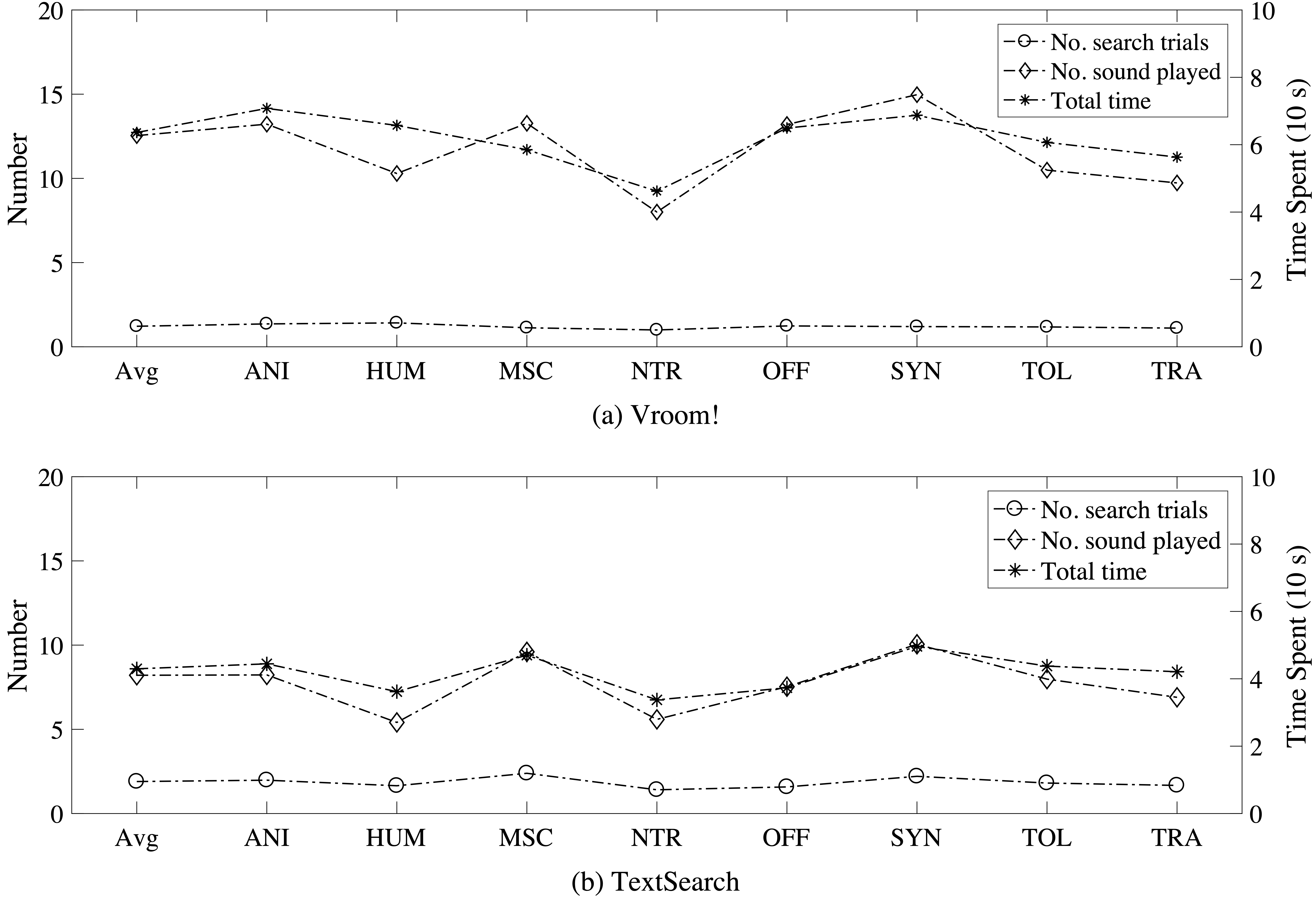
Figure 6. User behavior statistics for Vroom! and TextSearch. Each point in the plot is the mean value with std omitted for better visualization.
Second, Vroom! has significantly fewer search trials than TextSearch in all categories except HUM as shown in Table 1. Note that in HUM category the mean number of search trials in Vroom! is still lower than TextSearch, although it is not statistically significant. Considering that user satisfaction ratings for Vroom! in MSC, NTR, SYN, and TOL categories are significantly higher than those for TextSearch, this suggests that fewer search trials may lead to better search experience. Higher search efficiency can be achieved by requesting less queries from the user. It suggests that vocal-imitation-based search has advantages over the traditional text-based search in terms of search efficiency.
On the other hand, the average number of played sound candidates in each search using Vroom! is much larger than that of using TextSearch. As file names of returned sound candidates often contain semantic meanings, we believe that users can often skip listening to sound candidates when their file names seem irrelevant to the text query in TextSearch. For Vroom!, such "short cut" is not available and listening is often the only way to assess the relevancy.
Finally, the overall time spent on each search in Vroom! is significantly longer than that in TextSearch. This can be explained by the larger number of sounds played in Vroom! as well as the additional time spent to record and playback vocal imitations compared to typing in keywords.
Table 1. P-values of unpaired t-tests verifying if the hypotheses in the first column are statistically significant, at the significance level of 0.05.

Ranking of Target Sound
We visualize the target sound ranking distribution for both the proposed Vroom! and baseline TextSearch across different categories. Complimentary to User Feedback, it is an objective evaluation measure to compare the two search engine performance.
Please note that in Vroom! the target sound is always in the returned candidate list. But in TextSearch, given the user's query keywords, the target sound may or may not be in the returned candidate list. If the target sound is not in the candidate list, we treat the target sound rank as 999, which is greater than the number of sounds in each category. As shown in Figure 7, black and white bars indicate rank counts for Vroom! and TextSearch, respectively. The overlapping portion between the two systems is shown in grey. Some interesting findings can be observed as the following.
Figure 7. Comparisons of target sound rank in the returned sound list between Vroom! and TextSearch within each category.
First, target ranks in Vroom! are distributed more flattened within the range of maximal number of sounds in that category. But TextSearch shows a more polarized result that either the target sound ranks very high or has no rank at all. It indicates that the user may choose highly matched keywords of the target sound or cannot come up with relevant descriptions for that sound entirely. This is obvious in MSC, OFF, and SYN categories, by comparing the leftmost and rightmost white bars in the figure. For example in the SYN category, for users without music or audio engineering background, describing a synthesizer sound effect by text is very challenging (e.g., a sound effect named "eerie-metallic-noise.mp3" annotated with keywords of "alien", "eerie", "glass", and "metallic").
Second, in HUM, MSC, OFF, and TOL categories, Vroom! shows a smaller proportion of high ranks compared with TextSearch, while in other categories like NTR, SYN, TRA, Vroom! shows a higher proportion of high ranks. In both cases the target sound from Vroom! can be low ranked around several hundreds out of the entire returning candidate sound list. We argue that this is still different from the out-of-scope situation if no matched keywords can be found in TextSearch. In practice, Vroom! could return more than 20 sounds for the user to choose from, and could work with text-based search to reduce the candidate pool, target sounds in low ranks could still be possible to discover. Furthermore, as the returned candidate sounds are ranked based on the content similarity with the vocal imitation query, even if the target sound is low ranked, other high ranked candidate sounds may still align well with the user's taste.
SAT rating and target sound ranking indicate the subjective feeling and objective evaluation about sound search effectiveness of Vroom! compared with TextSearch. It suggests that vocal-imitation-based search has advantages over the traditional text-based search in terms of search effectiveness.
Sound Search in Lengthy Recordings
Another novel application is to search short sounds in lengthy recordings. Figure 4 shows the main workspace of the proposed interface. It consists of three main sections: Navigation Map,
Annotation Track, and Region Selection. The Navigation Map displays a waveform of an entire track and the currently labeled regions so that a user navigates and listens to them easily. The Annotation Track is a zoomed-in version of Navigation Map. A user can select regions or change their boundaries by mouse clicking and dragging. The Region Selection displays the top n candidate regions identified by the machine.
The user can listen to presented regions by clicking the items in the list and label it by clicking
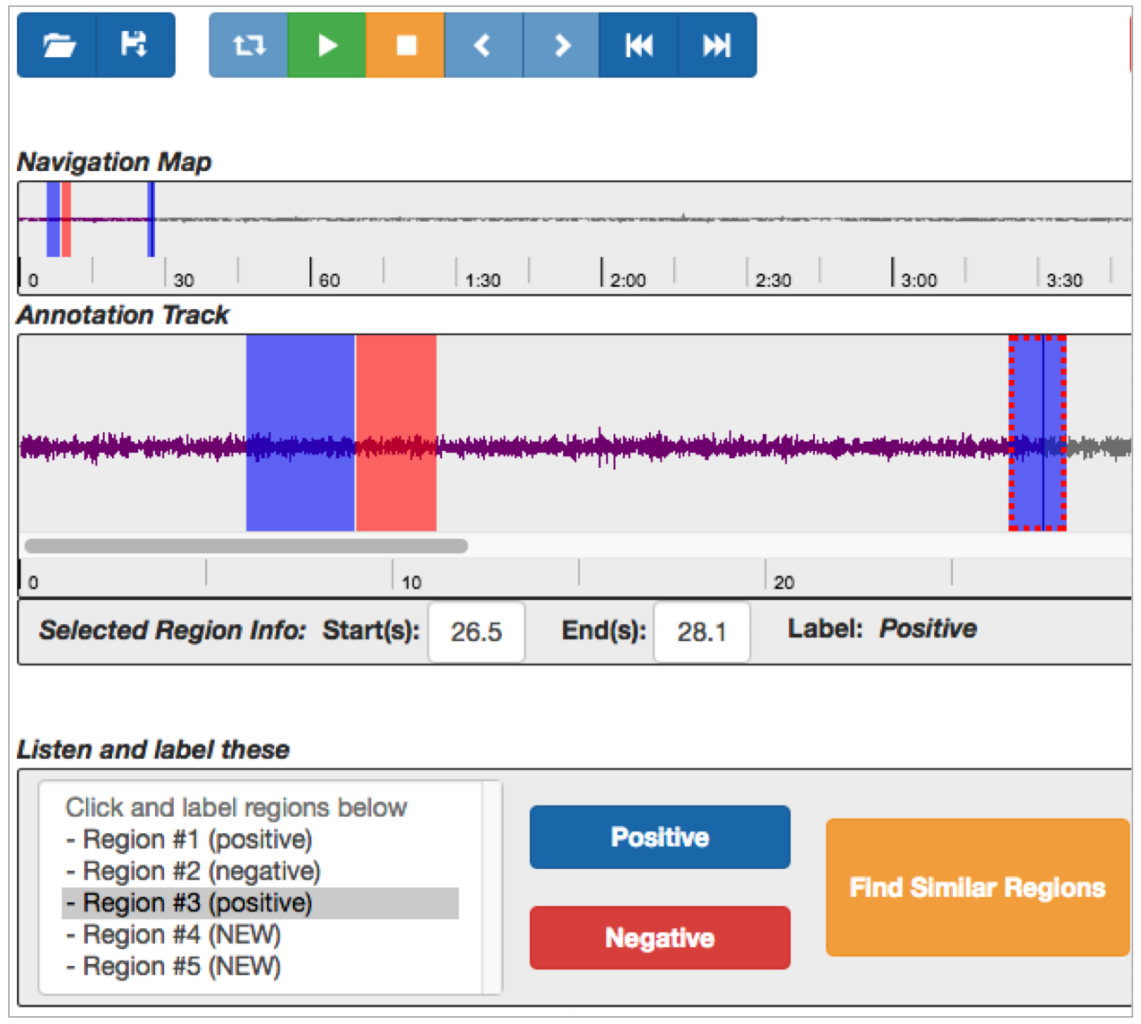
Figure 4. Screenshot of the Interactive Sound Event Detector
We tested this interaction design for audio search on the case of lengthy audio files containing short examples of the sounds the user seeks, see Figure 5. We created 12 minute-long audio tracks, each containing 11 different sound classes with 18 short examples of each class in the track and all events randomly distributed over the track. 20 participants were asked to find all examples of a target class of sound (e.g. human speech) in a file either using manual search or using our interface, where the user provides an initial example sound then vets the example sound events returned by the system. We considered a sound event correctly detected if the user-labeled region overlaps sufficiently with its ground truth (tolerance for the onset and offset: 1 second). The mean times that participants spent finding 80% of the sound events are 740 seconds for the manual annotator and 347 seconds for our new interactive detector. These results are statistically significant (Wilcoxon signed-rank test: p < 0.05). This indicates that search through lengthy sound files is twice as fast with our approach.
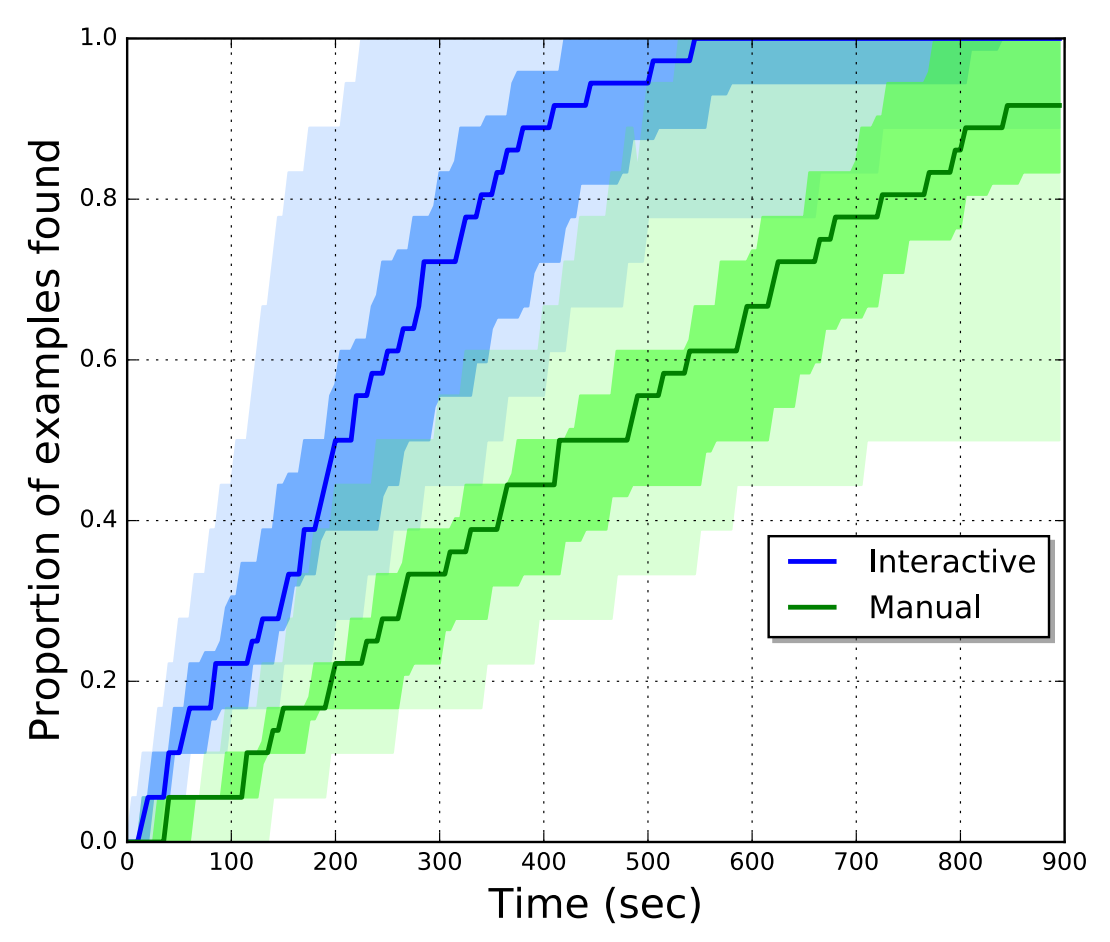
Figure 5. The proportion of examples found over time using two different interfaces, our proposed interactive system and a manual annotator
Last updated .

