RL-Duet: Online Music Accompaniment Generation using Deep Reinforcement Learning
|
This project is partially supported by the National Science Foundation under grant No. 1846184, titled " CAREER: Human-Computer Collaborative Music Making", and the Natural Science Foundation of China grant Nos. 61876095 and 61751308. Disclaimer: Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation. |
What is the problem?
This work is part of our project on "Human-Computer Collaborative Music Making", which aims to enable humans to collaborate with machines in ways that humans collaborate with each other to make music in real time. There are in general two types of collaborative music making. One is called call and response, e.g, the Magenta’s AI Duet, where the machine and human take turns to play. The other one is simultaneous play. In this work, we focus on the second type. In particular, we propose a reinforcement learning framework for online music accompaniment generation in the Western counterpoint style.

The proposed algorithm needs to satisfy two key properties: 1) online generation, 2) global coherence considering both intra- and inter-part interaction.
The Reinforcement Learning Framework
We cast the online music accompaniment problem into a reinforcement learning framework, where the music generator is trained with a reward model, which was further pre-trained to model intra- and inter-part interaction of counterpoint duets.
With reinforcement learning (RL), the music generator is trained to maximize the expected long-term discounted reward. Compared to maximum-likelihood-estimation (MLE)-based generation in the current time step, RL makes the model look into the future, taking the global coherence into consideration.
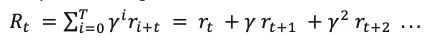
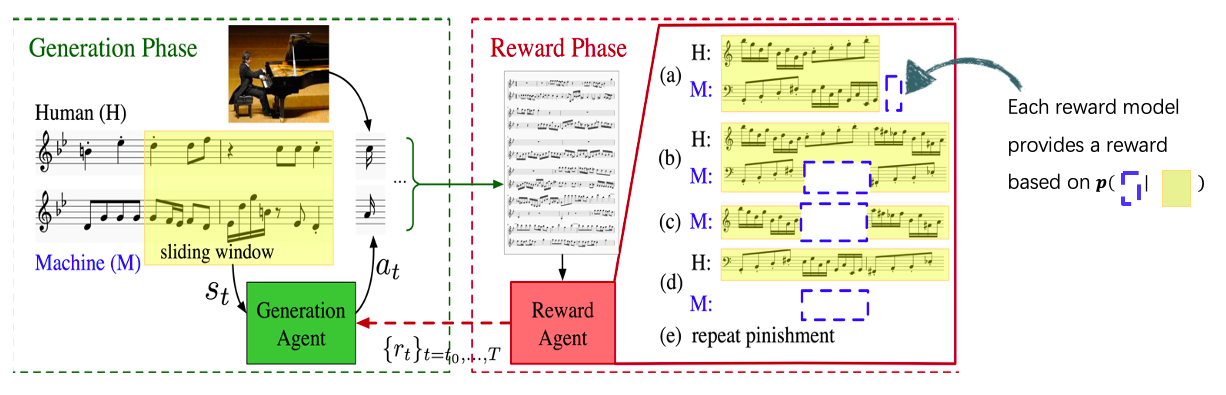
In each reinforcement learning iteration, there are two phases. First is the generation phase, the generation agent sequentially gives the counterpart token a_t based on the state s_t. After the improvisation of the whole music, the reward agent computes the reward for each action. Then these rewards are backtracked to calculate discounted reward and use RL to train the generation model.
Data-Driven Reward Agent
We train four reward models from data. Together with a rule-based reward, they are ensembled into a comprehensive reward agent. These four reward models are all trained with MLE, but with different inputs and outputs. As shown in the framework figure, the inputs are in yellow shadow, and the outputs are in blue dashed boxes. Rewards (a) and (b) jointly model two parts. Reward (c) gives rewards from the horizontal view, which emphasizes on the intra-part modeling. Reward (d) gives rewards from the vertical view. The rule-based reward (e) gives a punishment (negative reward) to the generated notes, if the same pitch is repeated for many times.
Results
We compare RL-Duet with two baselines. One is an MLE-based generation model, which shares the same model architecture with RL-duet. The other is RL-rules, which is trained with reinforcement learning but uses some of the rules modified from SequenceTutor.
Objective Results
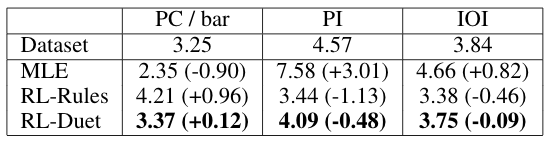
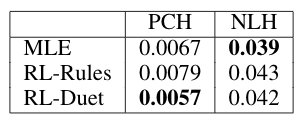
These objective metrics are suggested in "On the evaluation of generative models in music." For PC/bar, PI, IOI, we show the statistics calculated on the test dataset and on the generated music by each algorithm, and their differences. For PCH and NLH, we calculate the earth moving distance between the statistics on the test dataset and the generated music by each algorithm.
- PC/bar: pitch count per bar
- PI: average pitch interval
- IOI: average inter-onset interval
- PCH: pitch class histogram.
- NLH: note length histogram.
Subjective Results
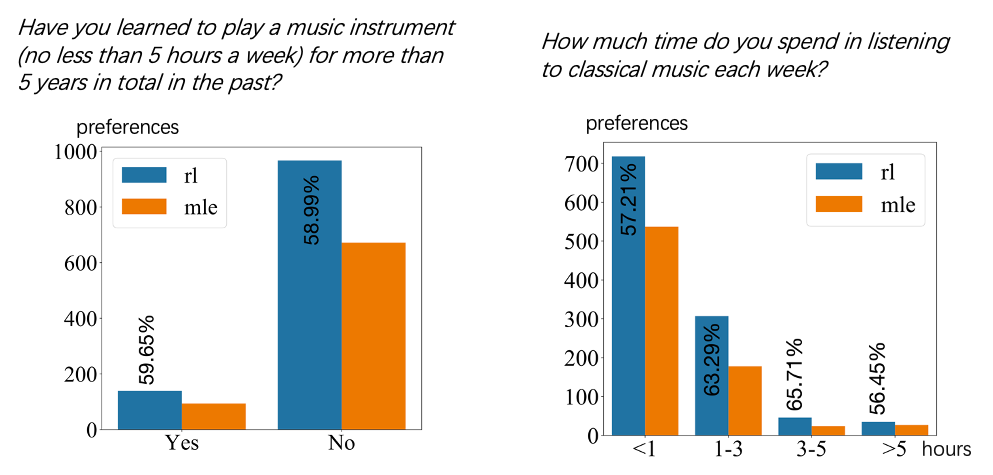
We also conducted a paired subjective evaluation. Each subject was presented with a pair of two duet excerpts with the same human part. These two duets came from RL-duet and MLE model. RL-rules was excluded, since we observed some apparently bad generations of RL-rules. The participants' preferences with their background are shown in these two figures.
Examples
Example 1
This is an interesting example. In the human part, which comes from Bach chorales, the first four measures are repeated. The machine part is generated online. In the beginning of the fourth measure, the model has no idea about the repeat. It generates a G4 quarter note. It then identifies the repeat in the human part, hence also repeats its first four measures. This repeat continues until the ninth measure.

Example 2

Example 3

Publication
[1] Nan Jiang, Sheng Jin, Zhiyao Duan, and Changshui Zhang, RL-Duet: Online music accompaniment generation using deep reinforcement learning, in AAAI, 2020.